
F* (pronounced F star) is a functional programming language with a dependent type system that supports verification. What follows is a story about my experiences with F* and a concluding opinion why languages like F* could be useful for the working software developer.
There is a big project using F* and related tools for the ambitious goal to build a verified implementation of TLS.
So far, judging from the website, there is a verified efficient implementation of the relevant cryptographic primitives but their implementation of the protocol is not yet verified. That is certainly already a great achievement and got me interested F*.
Setting it up
There is a F*-Tutorial which comes with an online editor, which is great if you just want to play a bit with the language. You don’t have to install anything, provided you have a recent mainstream browser. The tutorial is fun to do, but after I spent some time on it, I wanted to know what it is like to use F* not on a prescribed path.
Sooner or later, you probably want to install it on your machine, which is not a problem at all, if you are on linux system and an emacs user. There is a binary and an emacs mode which is also easy to install on windows but the combination was somehow forbiddingly slow on my (fast) machine. In the following, pictures will show excerpts from the emacs-mode.
Programming in F*
Let me first show you, what programming in F* looks like. Here is a definition of the commonly known (higher order) function “filter” which takes a predicate (function to bool in this case) and a list and returns the “sublist” of all things on the list matching the predicate:

The arrows and strange dots are just “->” and “::” rendered by the emacs mode. Otherwise, it is exactly the pattern matching definition that would also work in OCaml or F# (where you can write exactly the same thing):
The second argument “l” is matched against the two things a list might be, either the empty list “[]” or a list with consisting of some first element “x” and a list “xs”. In the first case, we are done and in the second case we decide if “x” should be in the result list and recursively call “filter” to deal with the “xs”.
The type of “filter” can be inferred by F*, but we could have declared it before the definition like this:

The alpha is really fancy emacs-mode rendering for ” ‘a ” and stands for an arbitrary type. This is also the type F* would infer, since what we did does not require anything special from the element type of the lists.
So the declaration says that our function takes some predicate “p” a list of things p may be applied to and returns a list of the same type just with “Tot” written in front of it. The latter tells us, that filter is a total function, i.e. it terminates and will not throw an exception (I guess there is a bit more to it, but so far that explanation worked well for me). There is also a modifier “ML” which would tell us, that the function behaves like a function in OCaml – so it could throw runtime exceptions or loop forever. After introducing you to some verification features, I will tell you why this distinction is important here.
Let us first rewrite our declaration a bit:

I replaced the alpha with a fixed type, the natural numbers (that will simplify things…) and introduced variables “p” and “l” that we can use now to construct types. What kind of types? Well, in this case, I want to construct a replacement for “(list N)” which tells us a bit more about the result of filtering a list. One reason to have types is to make sure, that the result of some construction meets a specification. Usually these kinds of specifications are quite coarse and might just tell you, that the result is an integer. So far, the specification of the filter function only tells us, that the result will be a list of natural numbers. In F*, we can do a lot more. The following specifies the result of filter to be the sublist of all elements of “l” that satisfy “p”:

Between the curly braces, I put a formula in predicate logic, which describes this specification. The ” ∧” is a logical “and”, the “∀” is the “forall” from math and ” element x l’ ” is some function which evaluates to true if x is an element of l’ and false if this is not the case.
Now, one of the things that make me happy when playing with F* is that the definition of filter I gave in the beginning checks against this new declaration as is. This is due to F* using a problem solver to prove that our specification is satisfied and the not-so-random coincidence that to prove the formula, you can use the same structural induction on the list as we used to recursively define “filter”.
For completeness, here is my definition of “element”:

The “#a:eqtype” means, that “a” is some type such that comes with a total equality function for terms of type “a”. The natural numbers used above are such an “a”. Btw: Those natural numbers are not limited in size, like e.g. “unsigned int”. They behave a lot like “BigInteger” in some languages and are certainly not fast, but they are good for proving things.
And now, I should tell you, that the declaration of “filter” which nicely specified what filter does, is probably not what you should do. In fact, it is usually better to split things into definitions and “Lemma”s. So here is again the original definition of filter (with inferred type) and a Lemma about it:
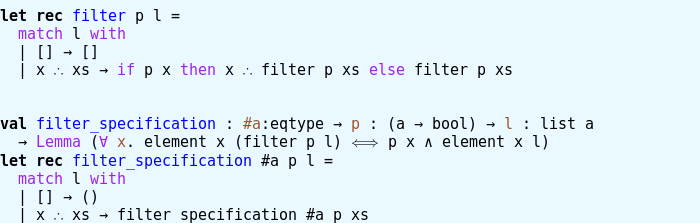
The “Lemma” is again like “Tot” above – it modifies the type. Technically, “filter_specification” is a function, but the only thing important here, is if its definition (“let rec filter_specification = […]”) type checks with the declaration (“val filter_specification […]”) given – because that means that the definition is a proof of the proposition encoded in the declaration. In particular, it is not important what this function returns. In fact, “Lemma” produces a type all of whose terms are equal.
Verifying Project Euler exercises
First thing I usually do when checking out a new programming language is to solve a couple of Project Euler exercises to get fluent in the basic constructions. So, I thought, why shouldn’t I try the same with F* and prove something about my solution code?
Problem 1 asks us to add all multiples of 3 and 5 below 1000. Usually, my mind drops the “below” and I get a wrong result. But not so this time! Here is my definition of the natural numbers below 1000, which produces the correct list of numbers, since specifying precisely what it is made me read the problem text very carefully:

Now, “naturals_below_1000” is specified by its type, which turned out to work well in this case, since it is not a general purpose function I will reuse.
Now for the task at hand, we need to filter numbers that are multiples of 3 or 5. I took the liberty to equivalently say, numbers divisible by 3 or 5:
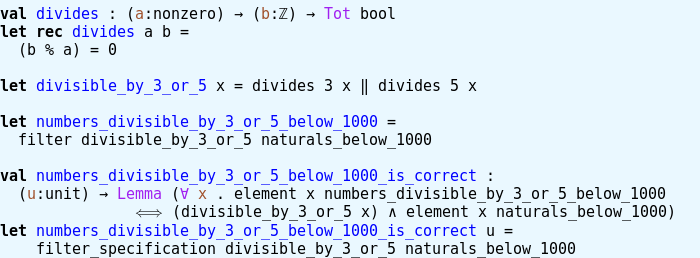
I used modulo arithmetic “%” defined in some library to have an easy definition of “divides”. Also note, that I use definitions in proving that I defined the correct list. Both are a bit fishy if I were to claim that I proved some term in my program meets some mathematical definition commonly used for the concepts in the problem text. So you could call that lazy or efficient according to taste.
Now, the number which the exercise asks for can be defined:

F* can not just check if everything is correct but also evaluate expression. In particular the expression “ex1” which turns out to be the correct answer to the problem.
Is it of use for the working software developer?
I used Scala some years ago to develop a large prototype and, while there were some pains, it worked about as well as expected and I’m quite sure it would have been less fun and less efficient to use Java for the same project. One important point in the decision to use Scala was the possibility to use Java libraries.
F# has the same kind of advantage and I learned to love its type system from OCaml, which apparently was the basis for F#. So for the same reasons that made Scala work for me when constructing prototypes, I could decide to use F# in similar situations. I don’t know, how realistic my hope is, that F* can be used on top of F# one day, but that would be a great improvement over just having F# which is already something I look forward to. So far, it as possible to extract F# code from an F* program.
Usually, tools like F* are thought of and presented as tools to effectively prevent bugs, i.e. catching all of them no matter the effort. I think, what we need for our daily programming tasks are tools for preventing bugs efficiently. My guess is, that dependent types in a practical language like F# are such a tool. This is of course a heavily biased view, since I have a background involving some dependent type theory, which makes me blind to the effort of learning how dependent types work.
One problem with dependently typed languages is, that small changes can break lots of proofs that took effort to prove. This is particularly bad, if you spell out the proofs in all detail and it means refactoring can become quite expensive.
From what I have seen, the use of a problem solver when type checking reduces this problem quite a bit, so this might not be a real issue here and with other dependently typed languages that do something similar. And of, substitute technologies that achieve similar goals, like unit tests or comments, also increase refactoring work.
So ultimately, apart from the fun, I also look forward at using F* as tool. As I mentioned before, I already knew about dependent types and could translate what I see when learning F*, so I can’t tell you how much effort it takes, if you don’t already know those things. But what I can tell you is, that learning dependent type theory was certainly among the most rewarding scientific experiences in my life, so maybe you want to do that anyway.
