In a way, this post is also about Test Driven Developement and *Type* Driven Developement. While the two share the same acronym, I always thought of them as different concepts. However, as I recently experienced, when the two concepts are used in a dependently typed language, there is something like a fluid transition between them.
While I will talk about programming in the dependently typed language Agda, not much is needed to follow what is going on – I will just walk through an exercise and explain everything along the way.
The exercise I want to use, is here. It talks about a submarine, its position and certain commands, that change the position. Examples for commands are forward 1, down 2 and up 3. These ‘values’ can be used just like that with the following definition of the type of commands:

Agda can be used in a very mathy way – this should really be read as saying, that the type of commands is a Set and there are three constructors (highlighted green) which take a natural number as argument and produce a command. So, using that application is just juxtaposition, we can make the following definitions now:

Now the exercise text explains, how these commands can be applied to the position of the submarine. Working as a software developer, I built the habit of turning specifications like that into tests. Since I don’t know any better, I just wrote ‘tests’ in Agda using equations to translate the exercise text – I’ll explain the syntax below:

Note that the triple equal sign is different from what we used above. Roughly, this is because it is the proposition, that some tings are equal, while the normal equal sign above, was used to make definitions. The code doesn’t type check as is. We haven’t defined ‘apply’ and it is not valid Agda to just write down equations like that. Let’s fix the latter problem first, by turning it into declarations and definitions. This will actually define elements of the datatypes of equality proofs – but I’m pretty sure you can accept these changes just as boilerplate we have to add to our equations:

Now, to make the examples type-check, we have to define ‘pos’ and ‘apply’. Positions can be done analogous to commands:

(Here, the type of ‘pos’ just tells us, that it is a function taking two natural numbers as arguments.) Now we are ready to start with ‘apply’:

So apply is a function, that takes a ‘Command’ and a ‘Position’ and returns another ‘Position’. For the definition of ‘apply’ I just entered a questionmark ‘?’. It is one of my favorite features of Agda, that terms can be left out like this before type checking. Agda still checks everything we have given so far and will give us a lot of information about what ‘?’ could be. This is called ‘interacting with a hole’. Because, well, it is a hole in your code and the type checker is there to tell you, which things might fit into this hole. After type checking, the hole and what Agda tells us about it, will look like this:
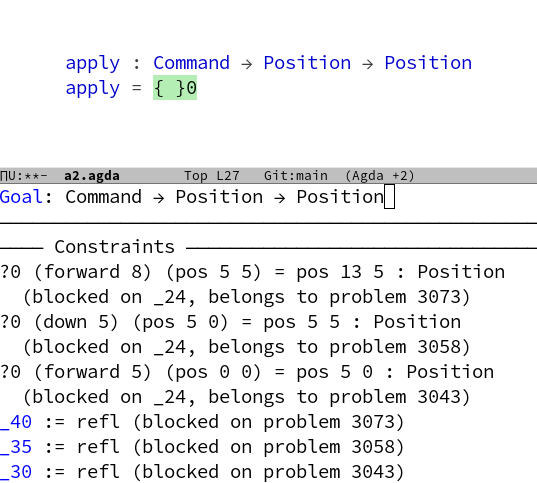
This was type-checked with a couple of imports – see my final version of the code if you want to reproduce. The first thing Agda tells us, is the type of the goal and then there is some mumbling about constraints with some fragments, that look like they have something to do with the examples from above – the latter is actually not information about the hole, but general information about the type checking. So lets look at them to see, if the type checker has to say anything:

Something is yellow! This is Agda’s way to tell us, that it does not have enough information to decide, if everything is okay. Which makes a lot of sense, since we haven’t given a definition of ‘apply’ and these equations are about values computed with ‘apply’. So let us just continue to define ‘apply’ and see if the yellow vanishes. This is analogous to the stage in TDD were your tests don’t pass because your code does not yet compile.
We will use pattern matching on the given ‘Command’ and ‘Position’ to define ‘apply’ – the cases below were generated by Agda (I only changed variable names), and we now have a hole for each case:

There are various ways in which Agda can use the information given by types to help us with filling these holes. First of all, we can just ask Agda to make the hole ‘smaller’ if there is a unique canonical way to do so. This will work here, since ‘Position’ has only one constructor. So we get new holes for arguments of the constructor ‘pos’ and can try to fill those.
Let us focus on the first case and see what happens if we enter something not in line with our tests:

If we ask Agda, if ‘h+d’ fits into the ‘hole’, it will say no and tell us what the problem is in the following way:
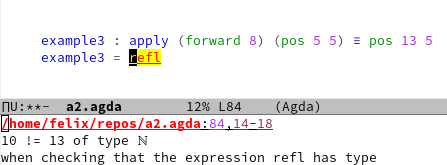
While this is essentially the same kind of feedback you would get from a unit test, there are at least two important advantages to note:
- This is feedback from the type checker and it is combined with other things the type checker can tell you. It means you get a lot of feedback at once, when you ask Agda, if something you wrote fits into a hole.
- ‘refl’ is only a simple case of the proves you can write in Agda. More complicated ones need some training, but you can go way beyond unit tests and ‘check’ infinitely many cases or even better: all cases.
If you want more, just try Agda yourself! One easy way to do that, is to use Ingo Blechschmidt’s Agdapad, which let’s you try Agda in your browser.

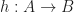 for a morphism from object
for a morphism from object  to object
to object  .
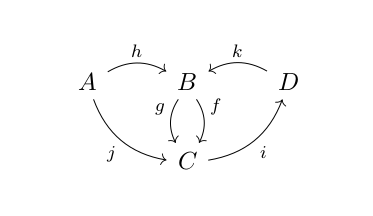
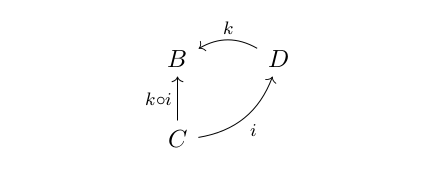
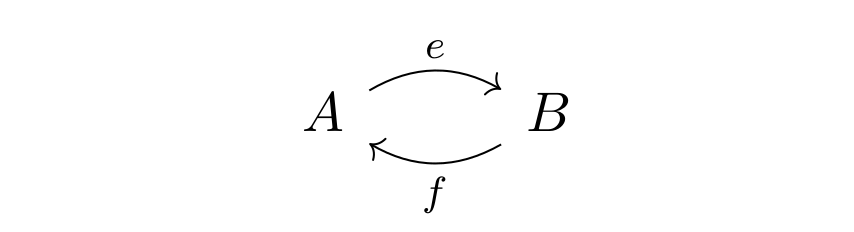
. ” can only be applied to morphisms, if they form “a line”. For example, if we have morphisms like k and i in the picture below, in a category, there will be a new morphism “
” can only be applied to morphisms, if they form “a line”. For example, if we have morphisms like k and i in the picture below, in a category, there will be a new morphism “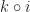 “:
“:
 ” is on the right in “
” is on the right in “
 and
and  returns a morphism
returns a morphism 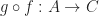

 ,
, 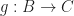 and
and  , we have:
, we have: 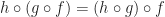
 we have:
we have: 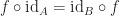
 . “
. “ ” is defined to be
” is defined to be 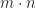 .
.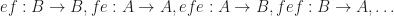 and an identity for
and an identity for 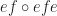 is
is  .
.
 be a labelled directed graph with edges
be a labelled directed graph with edges  and nodes
and nodes  . Then there is a category
. Then there is a category 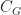 with objects
with objects 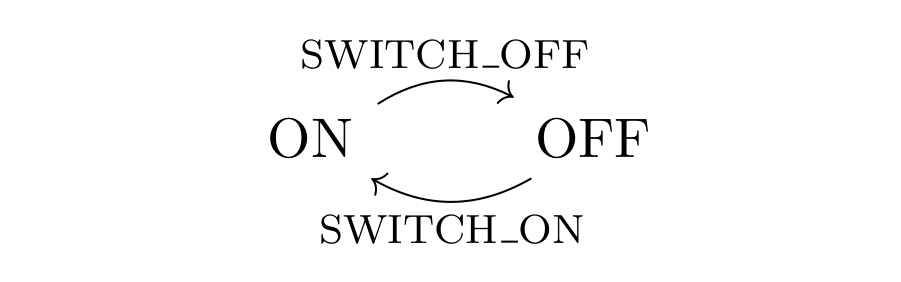
 ” satisfying these two laws:
” satisfying these two laws:

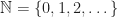 with addition.
with addition.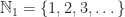 with multiplication.
with multiplication.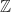 with addition.
with addition.![[1,2,3,\dots]](https://s0.wp.com/latex.php?latex=%5B1%2C2%2C3%2C%5Cdots%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
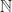 with addition and List({1}) are of the same form, witnessed by the following renaming scheme:
with addition and List({1}) are of the same form, witnessed by the following renaming scheme:![0 \mapsto []](https://s0.wp.com/latex.php?latex=0+%5Cmapsto+%5B%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![1 \mapsto [1]](https://s0.wp.com/latex.php?latex=1+%5Cmapsto+%5B1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![2 \mapsto [1,1]](https://s0.wp.com/latex.php?latex=2+%5Cmapsto+%5B1%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![3 \mapsto [1,1,1]](https://s0.wp.com/latex.php?latex=3+%5Cmapsto+%5B1%2C1%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

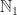 , the integers and the monoid of maps on a set, all of the examples above are free monoids. There is also a nice abstract definition of “free”, but for the purpose at hand to describe a special kind of monoid, it is good enough to say, that a monoid M is free, if there is a set A such that M is of the form List(A).
, the integers and the monoid of maps on a set, all of the examples above are free monoids. There is also a nice abstract definition of “free”, but for the purpose at hand to describe a special kind of monoid, it is good enough to say, that a monoid M is free, if there is a set A such that M is of the form List(A). I
I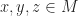 be elements of a monoid
be elements of a monoid  with operation “
with operation “ is identified with
is identified with 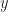 . Then, denoting equivalence classes with
. Then, denoting equivalence classes with ![[\_]](https://s0.wp.com/latex.php?latex=%5B%5C_%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) it is not clear if
it is not clear if ![[x] \cdot [y]](https://s0.wp.com/latex.php?latex=%5Bx%5D+%5Ccdot+%5By%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) should be defined to be
should be defined to be ![[x\cdot z]](https://s0.wp.com/latex.php?latex=%5Bx%5Ccdot+z%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) or
or ![[y\cdot z]](https://s0.wp.com/latex.php?latex=%5By%5Ccdot+z%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
.  “, but this would be besides the point of this post – what those properties are will not be defined in a formal mathematical way. If I am in doubt about equality while programming, I am concerned about properties relevant to the problem I want to solve. For example, in almost all circumstances I can imagine, for a list, a relevant property would be its length, but not the place in the computers memory where it is stored.
“, but this would be besides the point of this post – what those properties are will not be defined in a formal mathematical way. If I am in doubt about equality while programming, I am concerned about properties relevant to the problem I want to solve. For example, in almost all circumstances I can imagine, for a list, a relevant property would be its length, but not the place in the computers memory where it is stored. , so as long as we just add a double to a number with a short decimal representation while staying in the same order of magnitude, we can reproduce the precise numbers from doubles by setting the scale (which amounts to rounding) of our double as a BigDecimal.
, so as long as we just add a double to a number with a short decimal representation while staying in the same order of magnitude, we can reproduce the precise numbers from doubles by setting the scale (which amounts to rounding) of our double as a BigDecimal.