
If you happen to work on a system that scales to the size of an IT landscape, your worst bet is to let it evolve by circumstances. You want to have a plan and act upon that plan. The base for your plan could be a landscape map, which we talked about in the first part of this series. Upon drawing the map, you want to interpret it in order to find the strong points and weak spots. We’ve talked about assessing the map in the second part of this series.
In this blog article, we look at ways to improve our IT landscape towards the goal of overall stability.
Our mission statement
If we want to improve things, we need to know in what aspect the improvement should occur. At the scale of an IT landscape, overall stability is a commonly desired trait. This doesn’t mean rigidity, where you cannot change a thing in the landscape lest the whole thing breaks. It also doesn’t mean that ever part of our landscape needs to be stable itself. Overall stability means that even with the inevitable outage or replacement of a part, the whole system still works. The system is resilient to change and failure, at least resilient enough for the organization working with the system.
If our mission is to improve towards overall stability, we need to work on the relationships between our services (or assets, as we called them earlier, because “service” is a greatly overloaded term) more than we need to work on the service itself.
This doesn’t mean that individual stability of an asset isn’t important. It certainly is, but more often than not, you cannot improve this single value that much. What you can iterate on with recognizable effect is limiting the consequences of lacking individual stability.
Our mantra
The fundamental rule that brings overall stability is the “dependency rule” of the clean architecture that is meant for internal software application architecture. But if we see our IT landscape as one big application (software or not might make less of a difference than thought), we can apply the rule without modification:
All dependencies point towards the center (inside) and never in the opposite direction (outside).
That’s it. You define a center of your map and have all dependencies point towards it. This results in a structure of “rings” around the center that denote different levels of stability. The dependency rule can be rewritten as such:
All dependencies point from the less stable asset to the more stable asset and never in the opposite direction.
If you think of stability only in terms of “service availability” that tells you the percentage of time you can utilize the service without degradation, you’re thinking too short. Stability also means stable interface and stable implementation. You can have a really rock solid ISDN internet connection at the center of your IT landscape map, if your ISP discontinues the technology, the lack of implementation stability will force you to change the asset and hope that all dependent assets (basically your whole map) are not affected by the change.
Planning for obsolescence
Trying to bring the relationships between your assets in congruence with their significance for your IT landscape is the central work of an IT architect. The main question is always: What happens if this asset needs to be replaced?
In IT, there is no such thing as an “eternally working asset”. I’m not well-versed in more physical domains like mechanical engineering to say that this an univeral invariant, but in my field of speciality, everything changes eventually.
If you create an IT landscape where every asset can be replaced with manageable effort and predictable consequences, you’ve created an overall stable system. You can probably improve the availability of parts of it, but you won’t need to overhaul the whole thing over and over again. Your IT landscape is ready to grow, evolve and change, but it does so in a controlled manner and without compromising the mission.
Anti-obsolescence patterns
On your way from your current map to your anticipated one, you’ll recognize recurring patterns that you employ to solve dependency problems or improve the longevity of overall structures. Here are three patterns that have helped me in my endeavours:
Protected variation
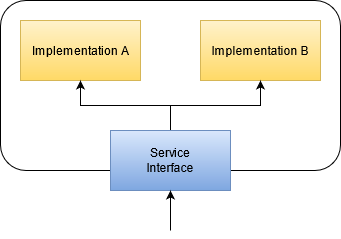
If you have more than one implementation for basically the same service (like the example of an internet connection), you probably want the rest of the map to not know about the multiplicity. In this case, you introduce an additional asset that acts as a router between the implementations. Think of the router (or service interface) as a guarding wall for your service implementations. It acts as a “portal” to the real service and can be paper-thin (at least for now). If you want to improve the runtime availability of your service, the router can also act as a load balancer and a circuit breaker. The important rule is that all outside relationships only point to the router, not the actual implementations.
Opinionated interface
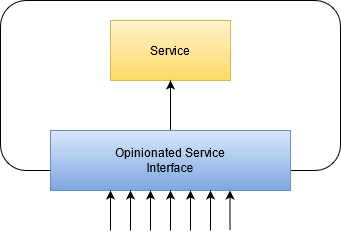
If you find an asset that has a lot of incoming dependencies, you’ve found a change risk. If you swap the service for a newer version with a similar, but not quite equivalent interface, you’ll find that you have to adjust lots of dependent assets in oftentimes surprising fashion. You can reduce your surprise by introducing a “portal” interface, just like you did in the protected variations, but without the variations. The portal or “opinionated service” interface offers everything your other assets require of the original service, but nothing more. It captures the “opinion” of your organization towards the service. When you introduce such a portal, it is nothing more than a forwarding service that maybe handles authentication itself. If you plan to swap the service, the portal becomes your requirement list and its new implementation will convert data back and forth.
If you find that your portal gets to big, you could think about multiple portals with their own separated “opinion” about the service, all forwarding to the same “source of truth”:
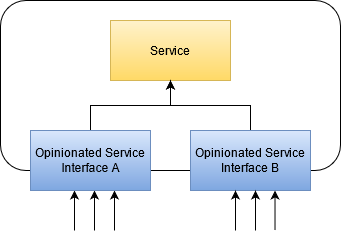
Now you need to maintain several interface services, but they separate different concerns or contexts into separate assets, which might help with future migrations. Chances are, if there are separate concerns, that they will be provided by separate assets in the future.
Circular portals
The most nasty thing to occur on your map is the ring (see part II of the series). In its smallest form, its just two assets requiring each other:

There are no easy ways out of this situation. But we can make some steps in the right direction and see where it takes us. The first step is introducing buffer assets that act as stand-ins for the real asset:
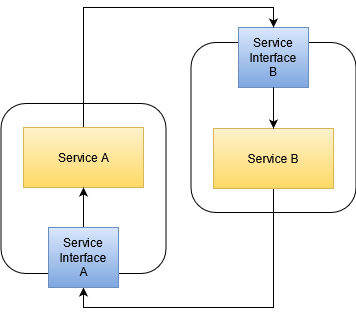
This doesn’t break the ring yet, but it gives us a chance to do so later. The service interfaces are opinionated and maybe even tailored specifically to the service using it. This reduces the “area of dependency” to its minimum. With a little luck, we find that Service A requires things of Service B that, if isolated, don’t require things of Service A themselves. If that’s the case, we can work on splitting Service B in two parts: One dependent on Service A, but not required by it and one indepedent of Service A, but needed by it. This would break the ring and give us a long chain that is much easier to work with. The problem is: None of this is guaranteed. In the worst case, you’ll still end up with your circular dependency with extra steps and nothing can be done about it.
Conclusion
When you begin to work with your IT landscape map, you begin to transform your assets from what they provide to what others actually require from them. Minimizing the relationships between assets, if not by number then at least by scope, is an appreciable improvement that gives you leeway to make changes in your actual IT setup without compromising the overall structure.
If you accompany your journey towards the best-fitting IT landscape with your map, you always have a plan at hands that you can show to people to form a shared understanding of the current state and the desired outcome. And if you keep old versions of your map in the archives, you can sometimes look back and see how far you’ve come yet.

One thought on “The IT architect, Part III: Improve your environment”