
When I was eight years old, my parents bought our first computer. With it came a tiny monochrome display that could be used to show 80×25 characters in amber yellow. I’m typing this text on my most recent computer that is equipped with several displays that show a combined amount of nearly 27 million pixels with at least 2^24 colors each. I don’t dare to count the number of characters that are on screen right now. Something happened along the way.
The formative years
Me as an eight year old boy immediately “clicked” with that first computer. It became my destiny to unlock its full potential. I was delighted when my parents upgraded to a much better PC years later with a color display that could actually show 256 colors at once on a 14″ frame. It was still a CRT monitor, so the refresh rate was probably around 30 Hz and I remember the “fishbowl eyes” you got from longer computer sessions.
If we want to have a visual representation of this monitor, it looks like this:

My first own computer came with a 17″ CRT monitor, which was considered a luxury size and didn’t really fit on the desk. I used this monitor up until my first year of my studies. Nothing in my world would suggest that using more than one monitor per computer is even possible. This computer had a mouse without scroll wheel and no internet access:

When I studied computer science, I came in contact with a lot of people that all took computing and programming serious. Some had monitors the size of a freezer, which hinted at me (and my peers) that 17″ is not as lavish as we thought. But still, a computer had one CPU and one monitor. I scraped my money together and bought a 19″ flat panel CRT monitor. Flat panel just meant that the display area didn’t resemble a fish bowl by itself. It could run up to 60 Hz:

The professional setup
That was my personal computing situation when I founded my company in the third year of my studies. I knew that the equipment had to be better and more professional. Our first work computers still had one CPU and one monitor. It just happened to be gigantic 21″ CRTs. Our desks had extra depth to provide a healthy distance between eyes and display area. Those monitors were delicate enough to provide a “de-gauss” button that would unhinge random electronics around it if pressed:

This was how software was developed in the early 2000s. A “fast” computer with lots of RAM (1 GB were not unheard of), a magnetic harddisk with 160 GB of storage and still one CPU and one monitor. At least, they had internet access and a mouse with a scroll wheel now.

This setup lasted for four or five years, with better computers, but still the same old monitors. Then, virtually over night, the prices for the new and very cool TFT “flat panel” monitors dropped to readonable numbers. These monitors were really flat and very thin compared to the CRT fish bowls that hogged our desks. We were thrilled and replaced all of our monitors within one year.
The double setup
But just as the CPUs now got two “cores”, we didn’t just replace our one monitor, we doubled it. Every workplace now had two monitors:
And not just that. The monitors were bigger, better, smaller, easier on the eye and had a greater resolution (called WUXGA, essentially FullHD with some extra pixels on the vertical axis).
And we had two of them! This was a game changer because things that used to be done one after another could now be done in parallel – on the CPU and on the monitors. We began to dedicate screen estate to fixed activities:

The left monitor was the “coding space” while the right monitor was the “tryout space”. The actual distribution of activity to screen location differed from developer to developer, but we all agreed that we would not go back to single monitoring.
During that time, I was sometimes asked if two monitors “are worth the investment”. I blogged about it and I’m still convinced that a second monitor is the single most profitable investment you can do for a developer.
The triple setup
In the blog post above, I made one statement that I soon took back: A third monitor is not the game changer like the transition from one to two monitors, but – if the hardware issues are solved – the next step in the evolution that truly separates work, work result and communication:

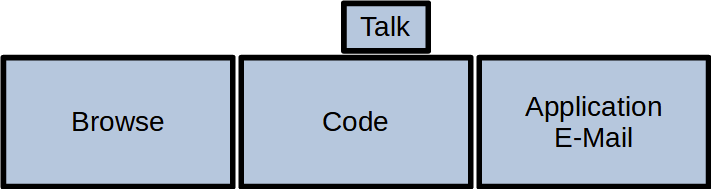
This setup is probably wider than your standard desk and requires a dedicated monitor stand, but it is the first time you can do the three essential things a programmer does in parallel:
- Browse the internet (like stackoverflow or an API documentation)
- Edit your source code in a fullscreen IDE
- Watch the result of your changes live (with hot reloading)
Your workflow essentially moves your head from the left (gather new knowledge) over the middle (apply the new knowledge) to the right (evaluate the result of the new knowledge) and back again for the next step:

This is our default workplace setup since 2018, with two possible resolution levels:
- QHD: 3x 2560 x 1440 pixels. This results in 11 million pixels per computer
- UHD: 3x 3840 x 2160 pixels. You now have almost 25 million pixels at your disposal
There is a biological limit what a human can see at once. This setup nearly fills your complete viewspace. You cannot fit a fourth monitor to the sides that you can really see. The only possibility to expand is now the vertical axis, with additional monitors above and maybe below.
The pandemic setup
I would probably still use the triple monitor setup if there hadn’t happened a fundemental change in the way we develop software in early 2020. In March 2020, we decided within days to abandon our office desks and retreat into home office workplaces that were improvised at first. Now, nearly two years later, all these workplaces are fully equipped and still continually improved. But not only our places changed, our communication as well. Video calls are a natural component of our workday now. And in my case, they happen in parallel to my normal work. So I had to dedicate screen space to videoconferencing. And I’ve done it by adding a fourth monitor:
This small monitor sits right next to the webcam, so if I look at my dialog partner, I also seem to look right into the camera. This setup adds a new distinctive activity to the mix:
I’ve described the other ingredients for a fully equipped home office in a previous blog post. You can see an early photo of my setup in this post.
Conclusion
And this is the setup I’m writing this blog post on. 27 million pixels that I can use to speed up my workflow by assigning dedicated working zones. If you had asked my in 2009 if I can imagine to double the amount of monitors and have nearly six times more pixels available, I would have said no way.
But by looking back to the beginning, I can see how the fundamentals of personal computing changed in every aspect. A computer is no longer “one CPU” and it doesn’t have only one monitor. Today’s displaying technology is capable of providing a lot of screen estate. The main limiting factor is our own imagination. Reaping the benefits of dedicated display areas is satisfying and increases your work troughput effortlessly.
If you ask yourself how your ideal monitor setup should look like, try to reflect on how you move your application windows around or how often you switch applications without moving your head. If you would like to make the switch without hiding the previous context, you’ve just found a use case for an additional monitor.
What is your monitor setup and your usage pattern with it? Tell us in the comments!
