
Conway’s Game of Life is a worthwhile coding kata that I’ve implemented probably hundreds of times. It is compact enough to be completed in 45 minutes, complex enough to benefit from Test First or Test Driven Development and still maintains a low entry barrier so that you can implement it in a foreign programming language without much of a struggle (except if the foreign language is APL).
And despite appearing to be a simple 0-player game with just a few rules, it can yield to deep theory, as John Conway explains nicely in this video. Oh, and it is turing complete, so you can replicate a Game of Life in Game of Life – of course.
But after a few dozen iterations on the kata, I decided to introduce some extra aspects to the challenge – with sometimes surprising results. This blog series talks about the additional requirements and what I learnt from them.
Additional requirement #1: Add color to the game
The low effort user interface of the Game of Life is a character-based console output of the game field for each generation. It is sufficient to prove that the game runs correctly and to watch some of the more advanced patterns form and evolve. But it is rather unpleasing to the human eye.
What if each living cell in the game is not only alive, but also has a color? The first generation on the game field will be very gaudy, but maybe we can think about “color inheritance” and have the reproducing cells define the color of their children. In theory, this should create areas of different colors that can be tracked back to a few or even just one ancestor.
Let’s think about it for a moment: When all parent cells are red, the child should be red, too. If a parent is yellow and another one is red, the child should have a color “on the spectrum” between yellow and red.
Learning about inheritance rules
One specific problem of reproduction in the Game of Life is that we don’t have two parents, we always have three of them:
Any dead cell with exactly three live neighbors becomes a live cell, as if by reproduction.
Rule #4 of Game of Life
We need to think about a color inheritance rule that incorporates three source colors and produces a target color that is somehow related to all three of them:
f(c1, c2, c3) → cn
A non-harebrained implementation of the function f is surprisingly difficult to come up with if you stay within your comfort zone regarding the representation of colors in programming languages. Typically, we represent colors in the RGB schema, with a number for the three color ingredients: red, green and blue. If the numbers range from zero to one (using floating-point values) or from zero to 255 (using integer values) or even some other value range doesn’t really matter here. Implementing the color inheritance function using RGB colors adds so many intricacies to the original problem that I consider this approach a mistake.
Learning about color representations
When we search around for alternative color representations, the “hue, saturation and brightness” or HSB approach might capture your interest. The interesting part is the first parameter: hue. It is a value between 0 and 360, with 0 and 360 being identically and meaning “red”. 360 is also the number of degrees in a full circle, so this color representation effectively describes a “color wheel” with one number.

This means that for our color inheritance function, the parameters c1, c2 and c3 are degrees beween 0 and 360. The whole input might look like this:
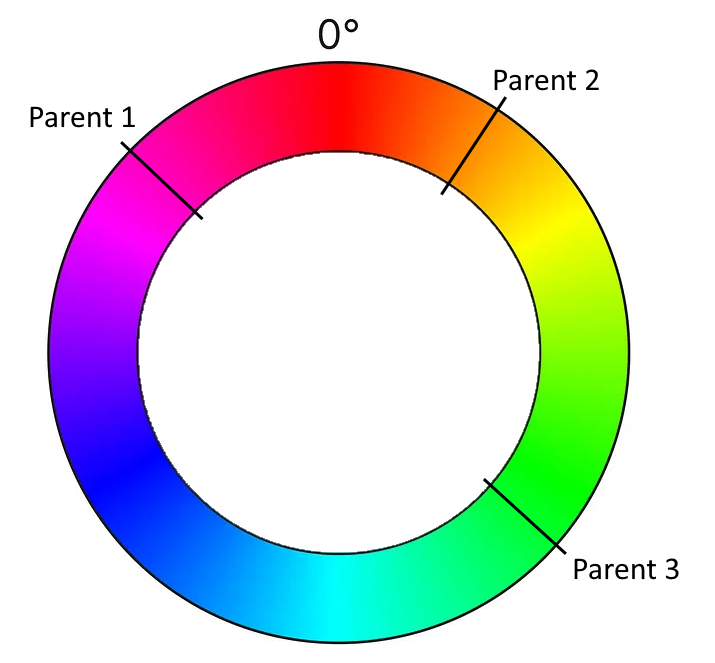
Just by looking at the graphics, you can probably already see the color spectrum that is suitable for the function’s result. Instead of complicated color calculations, we pick an angle somewhere between two angles (with the third angle defining the direction).
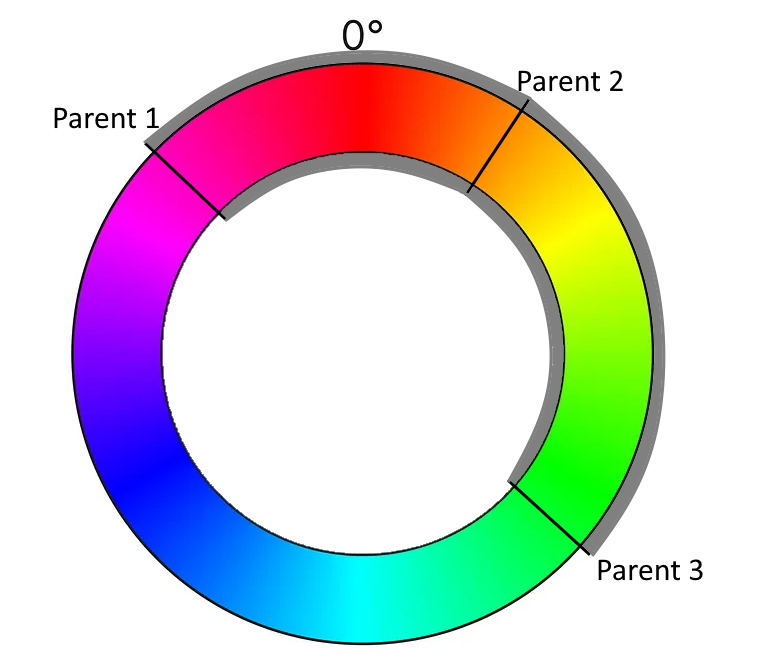
And this means that we have transformed our color calculation into a geometric formula using angles. We can now calculate the span between the “leftmost” and the “rightmost” angle that covers the “middle” angle. We determine a random angle in this span and use it as the color of the new cell.
Learning about implicit coupling
But there are three possibilities to calculate the span! Depending on what angle you assign the “middle” role, there are three spans that you can choose from. If you just take your parent cells in the order that is given by your data structure, you implement your algorithm in a manner that is implicitly coupled to your technical representation. Once you change the data structure ever so slightly (for example by updating your framework version), it might produce a different result regarding the colors for the exact same initial position of the game. That is a typical effect for hardware-tied software, as the first computer games were, but also a sign of poor abstraction and planning. If you are interested in exploring the effects of hardware implications, the game TIS-100 might be for you.
We want our implementation to be less coupled to hardware or data structures, so we define that we use the smallest span for our color calculation. That means that our available colors will rapidly drift towards a uniform color for every given isolated population on our game field.
Learning about long-term effects (drifts)
But that is not our only concern regarding drifts. Even if you calculate your color span correctly, you can still mess up the actual color pick without noticing it. The best indicator of this long-term effect is when every game you run ends in the green/cyan/blue-ish region of the color wheel (the 50 % area). This probably means that you didn’t implement the equivalence of 0° and 360° correctly. Or, in other words, that your color wheel isn’t a wheel, but a value range from 0 to 360, but without wrap-around:

You can easily write a test case that takes the wrap-around into account.
But there are other drifts that might effect your color outcomes and those are not as easily testable. One source of drift might be your random number generator. Every time you pick a random angle from your span, any small tendency of the random number generator influences your long-term results. I really don’t know how to test against these effects.
A more specific source of drift is your usage of the span (or interval). Is it closed (including the endpoints) or open (not including the endpoints)? Both options are possible and don’t introduce drift. But what if the interval is half-open? The most common mistake is to make it left-closed and right-open. This makes your colors drift “counter-clockwise”, but because you wrapped them correctly, you don’t notice from looking at the colors only.
I like to think about possible test cases and test strategies that uncover those mistakes. One “fun” approach is the “extreme values random number generator” that only returns the lowest or highest possible number.
Conclusion
Adding just one additional concept to a given coding kata opens up a multitude of questions and learnings. If you add inheritable colorization to your Game of Life, it not only looks cooler, but it also teaches you about how a problem can be solved easier with a suitable representation, given that you look out for typical pitfalls in the implementation.
Writing (unit) test cases for those pitfalls is one of my current kata training areas. Maybe you have an idea how to test against drifts? Write a comment or even a full blogpost about it! I would love to hear from you.
