
Last week, my colleague wrote about building blocks and how to achieve a higher-level language in your code by using them. Instead of talking about strings and files, you change your terms to things like coordinates and resources.
I want to elaborate on one aspect of this improvement, that aims at the separation of your intent from the current implementation. Your intent is what you want to achieve with the code you write. The current implementation is how you achieve it right now. I point out the transience of the implementation so clearly because it is most likely the first (and maybe even only) thing to change.
I have an example of this concept that is hopefully understandable enough. Let’s say that you build a system that gathers a lot of environmental data and stores it for later analysis and introspection. Don’t worry, the data consists mostly of things like air pressure, temperature and radioactive load. Totally harmless stuff – unless you find the wrong isotopes. In that case, you want to have a closer look and understand the situation. Most temporarily increased radioactivity in the air is caused by a normal thunderstorm. Most temporarily decreased radioactivity in the air is caused by a normal rain.
Storing all the data requires something like an archive. We want to store the data separated by the point of measurement (a “station”), the type of data (let’s call it “data entry type” because we aren’t very creative with names here) and by the exact point in time the measurement took place. To make matters a little bit more complicated, we might have more than one device in a station that captures a specific data entry type. Think about two thermometers on both sides of the station to make local heatup effects visible.
In order to reference a definite entry in our archive, we need a value for four aspects or dimensions :
- The station
- The data entry type
- The device
- The date and time
Thinking from the computer
If you implement your archive in the file system, you can probably see the directory structure right before you:
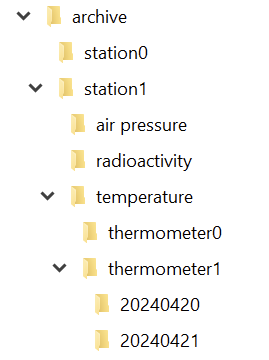
And in each directory for the day, we have a file for each hour:
So we can just write a class that takes our four parameters and returns the corresponding file. That is a straighforward and correct implementation.
It is also one of the implementations that couples your intent (an archive with four dimensions of navigability) nearly inseparably with your decisions on how to use your computer’s basic resources.
Thinking from the algorithms point of view
In order to separate your intent from your current implementation, you need to specify your intent as unencumbered from details as possible. Let’s specify our 4-axis archive nagivation system as a coordinate:
public record ArchiveCoordinate(
StationId station,
DataEntryType type,
DeviceId device,
LocalDateTime measurementTime
) {
}There is nothing in here that point towards file system things like directories or files. We might have a hunch of the actual hierarchy by looking at the order of the parameters, but it is easy to implement a hierarchy-free nagivation between coordinates:
public record ArchiveCoordinate([...]) {
public ArchiveCoordinate withStationChangedTo(
StationId newStation
) {
[...]
}
public ArchiveCoordinate withTypeChangedTo(
DataEntryType newType
) {
[...]
}
public ArchiveCoordinate withDeviceChangedTo(
DeviceId newDevice
) {
[...]
}
public ArchiveCoordinate withMeasurementTimeChangedTo(
LocalDateTime newMeasurementTime
) {
[...]
}
}The concept is that if you know one coordinate, you can navigate relative to it through the archive, without knowingly changing the directory or whatever implementation structure lies beneath your model layer. Let’s say we have the coordinate of a particular measurement of one thermometer. How do we get the same measurement of the other thermometer?
ArchiveCoordinate measurementForThermometer0 = new ArchiveCoordinate([...]);
ArchiveCoordinate measurementForThermometer1 = measurementForThermometer0.withDeviceChangedTo(thermometer1);We can provide methods that allow us to step forward and backward in time. We can provide our application code with everything it requires to implement clear and concise algorithms based on our model of the archive.
But there will be the moment where you want to “get real” and access the data. You might decide to let your current implementation shine through to your intent layer and provide an actual file:
public interface Archive {
Optional<File> entryFor(ArchiveCoordinate coordinate);
}That’s all you need from the archive to get your file. But you might also decide to prolong your intent layer and wrap the file in your own data type that provides everything your algorithms need without revealing that it is really a file that lies underneath:
public interface Archive {
Optional<ArchiveResource> entryFor(ArchiveCoordinate coordinate);
}The new ArchiveResource is a thin, but effective veneer (some might call it a wrapper or a facade) that gives us the required information:
public interface ArchiveResource {
String name();
long size();
InputStream read();
}Of course, we need to provide an implementation for all of this. But by staying vague in the intent layer, we open the door for an implementation that has nothing to do with files. Instead of a file system, there could be a relational database underneath and we wouldn’t notice. Our algorithms would still work the same way and read their data from ArchiveResources that aren’t FileArchiveResources anymore, but DatabaseArchiveResources.
You can probably imagine how you can provide the intent for data writing using the example above. If not, let me show you the necessary additions:
public interface Archive {
Optional<ArchiveResource> entryFor(ArchiveCoordinate coordinate);
ArchiveResource createEntryFor(ArchiveCoordinate coordinate) throws IOException;
}public interface ArchiveResource {
String name();
long size();
InputStream read();
OutputStream write();
}Now you can store additional data to the archive without ever knowing if you write to a file or a database or something completely different.
Summary
By separating your intent from your current actual implementation, you gain at least three things for the cost of more work and some harder thinking:
- Your algorithms only use your intent layer. You design it exclusively for your algorithms. It will fit like a glove.
- The terms you use in your intent layer shape the algorithm metaphors way better than the terms of your current implementation. You can freely decide what terms you’ll use.
- The algorithms and your intent layer are designed to last. Your current implementation can be swapped out without them noticing.
If this sounds familiar to you, it is a slightly different take on the “ports and adapters” architecture. The important thing is that by starting with the intent and naming it from the standpoint of your algorithms (application code), you are less prone to let your implementation shine through.
