
Every one of us has started somewhere. By telling you what my first computer was, I also convey a lot about the place and time my journey in IT started. For many of my fellows, it was a Commodore C64 or an Atari 500. But even if I don’t tell you about my first machine, there is a simple “magic spell” that you can cast to at least get a hint about the decade my first working days started, 15 years after my first contact with computers.
The spell is just one word: “container”. What a container is and how to use it is bound to the decades. Let me guide you through some typical answers.
Pre-2010 answer
If you entered the industry around the year 2000, a container was a big chunk of software that you preferably installed on an even bigger machine, the infamous “application server”. The container, or “servlet container”, “application container”, or, if you were with the right folks, “enterprise bean container” (in short: EJB-Container) was the central hub to host all of your web applications. If you deployed your application into the container, it handled the rest, like unpacking the web archive, providing resources and publishing to the internet. Typical names of containers were Tomcat, Jetty, JBoss or WildFly. You can probably see them around even today, because the concept itself is appealing. Some aspects of it inevitably lead to problems, though. Resource management was a big topic. Your application wasn’t expected to care for a database connection, a logging context or, sometimes, even security features, because the container provided those things to it. As you can probably imagine, that left your application crippled and unable to function outside a container.
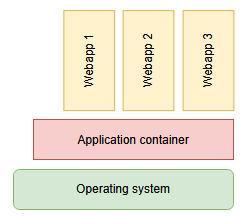
So if you onboarded more than ten years ago, your first thoughts reacting to the word “container” will be “big machine”, “slow startup” and “logging framework”. There cannot reasonably be more than one container per machine. Maintaining a cluster of containers would be the work of luminaries. Being asked to start a container on your developer machine is a dreadful endeavour. “Booting the container” is a reason to visit the coffee machine.
Post-2010 answer
But if you started your career less than ten years ago, your reaction to the word “container” will be different. Starting in 2013, a technology named “Docker” reinvented an old practice to isolate processes and package them into a transport format. Simplified enough, a container is just the RAM-based projection of an application image. You boot a container by loading the image into RAM. That’s some of the fastest things you can do on a computer (not really, but it fits the story better). Even better, because each container ideally contains just one small application or part of it, you don’t boot one container per machine, you can run dozens at the same time. Each container brings everything it needs with it and only relies on three common external resources being provided: Networking, persistent storage and a facility to dump logging output.
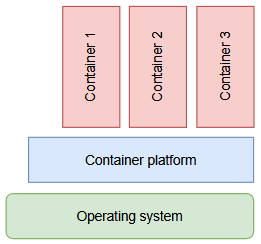
It is good practice to partition your application into several containers of the post-2010 kind. It is good practice to have them talk to each other over network, either real or simulated. The lines between actual computers get blurry real fast with this kind of containering.
As a youngster, your first thoughts reacting to the word “container” will be “just one?”, “scale up” and “log output management”. You see an opportunity to maintain a cluster of containers. Being asked to start a container on your developer machine is a no-brainer. “Booting the container” is a reason to automate your container infrastructure.
The reactions to the word “container” are very different, based on socialization period. In the old days, pre-2010 containers were boss fight adversaries. Nowadays, post-2010 containers are helpful spirits that just need to be controlled.
Post-2020 answer?
What better way to control the helpful spirits but to deploy them to an environment that handles unpacking, wiring, providing resources and publishing to the internet? Your application isn’t expected to care for topics like scalability, cluster robustness or load balancing. The environment, your container cluster platform, handles those things for you. There can only be one cluster platform per cloud. Being asked to start a cluster platform on your developer machine – well, that’s just not possible, sorry. Best we can do is a minified version of it. Our applications tend to function poorly outside a cluster platform.
As you hopefully can see, developers of all decades crave a thing they tend to call “container” that they can throw their software into to have it perform well without all the hassle of operations. But as soon as they give away responsibility for the environment, they also give away the possibility of comfortable “developer machine” operations. The goal is the same, just the technicality what exactly a “container” happens to be changes over time.
What is your “spell” that reveals a lot about the responder?
