Every one of us has started somewhere. By telling you what my first computer was, I also convey a lot about the place and time my journey in IT started. For many of my fellows, it was a Commodore C64 or an Atari 500. But even if I don’t tell you about my first machine, there is a simple “magic spell” that you can cast to at least get a hint about the decade my first working days started, 15 years after my first contact with computers.
The spell is just one word: “container”. What a container is and how to use it is bound to the decades. Let me guide you through some typical answers.
Pre-2010 answer
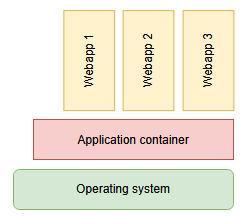
If you entered the industry around the year 2000, a container was a big chunk of software that you preferably installed on an even bigger machine, the infamous “application server”. The container, or “servlet container”, “application container”, or, if you were with the right folks, “enterprise bean container” (in short: EJB-Container) was the central hub to host all of your web applications. If you deployed your application into the container, it handled the rest, like unpacking the web archive, providing resources and publishing to the internet. Typical names of containers were Tomcat, Jetty, JBoss or WildFly. You can probably see them around even today, because the concept itself is appealing. Some aspects of it inevitably lead to problems, though. Resource management was a big topic. Your application wasn’t expected to care for a database connection, a logging context or, sometimes, even security features, because the container provided those things to it. As you can probably imagine, that left your application crippled and unable to function outside a container.
Pre-2010 containers
So if you onboarded more than ten years ago, your first thoughts reacting to the word “container” will be “big machine”, “slow startup” and “logging framework”. There cannot reasonably be more than one container per machine. Maintaining a cluster of containers would be the work of luminaries. Being asked to start a container on your developer machine is a dreadful endeavour. “Booting the container” is a reason to visit the coffee machine.
Post-2010 answer
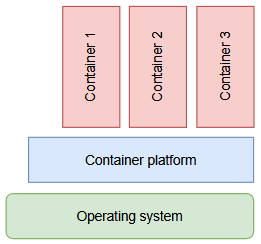
But if you started your career less than ten years ago, your reaction to the word “container” will be different. Starting in 2013, a technology named “Docker” reinvented an old practice to isolate processes and package them into a transport format. Simplified enough, a container is just the RAM-based projection of an application image. You boot a container by loading the image into RAM. That’s some of the fastest things you can do on a computer (not really, but it fits the story better). Even better, because each container ideally contains just one small application or part of it, you don’t boot one container per machine, you can run dozens at the same time. Each container brings everything it needs with it and only relies on three common external resources being provided: Networking, persistent storage and a facility to dump logging output.
Post-2010 containers
It is good practice to partition your application into several containers of the post-2010 kind. It is good practice to have them talk to each other over network, either real or simulated. The lines between actual computers get blurry real fast with this kind of containering.
As a youngster, your first thoughts reacting to the word “container” will be “just one?”, “scale up” and “log output management”. You see an opportunity to maintain a cluster of containers. Being asked to start a container on your developer machine is a no-brainer. “Booting the container” is a reason to automate your container infrastructure.
The reactions to the word “container” are very different, based on socialization period. In the old days, pre-2010 containers were boss fight adversaries. Nowadays, post-2010 containers are helpful spirits that just need to be controlled.
Post-2020 answer?
What better way to control the helpful spirits but to deploy them to an environment that handles unpacking, wiring, providing resources and publishing to the internet? Your application isn’t expected to care for topics like scalability, cluster robustness or load balancing. The environment, your container cluster platform, handles those things for you. There can only be one cluster platform per cloud. Being asked to start a cluster platform on your developer machine – well, that’s just not possible, sorry. Best we can do is a minified version of it. Our applications tend to function poorly outside a cluster platform.
As you hopefully can see, developers of all decades crave a thing they tend to call “container” that they can throw their software into to have it perform well without all the hassle of operations. But as soon as they give away responsibility for the environment, they also give away the possibility of comfortable “developer machine” operations. The goal is the same, just the technicality what exactly a “container” happens to be changes over time.
What is your “spell” that reveals a lot about the responder?
The year 2020 is coming to an end and we can finally relax a bit. In order to lighten up your mood, this blog entry is comprised entirely of humor, satire and plain silliness. Nothing in it has any resemblance with reality and you should not try any of this at work. But if, for whatever reason, you find something useful in here and go to revolutionize the world of software development, remember that we’ve called it first.
There are many programming languages for all sorts of purposes. If you’ve developed software for some decades, you saw them appear, getting useful and being forgotten over the span of time. But what will the future bring? Here are the descriptions of three programming languages that have their purpose, but the world is not ready for them. They aren’t even invented yet!
A programming language for long-lived projects
Most of today’s world source code is categorized as “legacy code”. This degatory term describes code that is old, unwieldy or just too clever for current programmers. Typical programming languages that have lots of legacy code include Cobol, C and Java. Most programmers don’t associate themselves with that code. It’s “other people’s” code. But there is one programming language that not only embraces the notion of “legacy code”, but in fact imposes it. This programming language is “Legacy”, the most productive one to produce heaps and heaps of, well, legacy code in short manners of time.
An unique feature of Legacy is that the code can be written at nearly the speed of thought, but is impossible to decipher even minutes later. A typical Legacy project doesn’t employ version control to differentiate between new and old code, but line numbers: Lower numbers indicate older code, while higher numbers are written more recently. To really drive this point home, every line of code needs to start with its line number, just like the good old BASIC did. An useful convention in Legacy is to choose the line number based on your current timestamp like 20201221181736 (the moment this text got written). Modern Legacy IDEs do this automatically for you.
(A cool but seldom used syntax feature that is based on the timestamp convention is the time-relative jump: You can address your jump target by absolute or relative line number, but even cooler is the relative amount of time: “jump -3d” resumes code execution at the line you wrote three days ago. Just remember: “jump +3d” is equivalent to undefined behaviour for most practical use cases. Only Legacy wizards can pull the “just-in-time jump” off in a useful manner.)
The most pressing issue about Legacy are its third-party dependencies: There are none. All dependencies are second-party dependencies, meaning they are much more involved in your project as usual. In order to compile or deploy a Legacy project, you need to have the exact version, down to the patch and oh-crap-i-forgot-hotfix number, of
the Legacy SDK
the compiler
the IDE
the Legacy runtime
and your text encoding
The last point might be surprising, but given the different versions of Unicode and even UTF-8, the Legacy ecosystem has chosen to follow the ideal of Python that dictates the indentation, but redirect it to the parts outlined above. You don’t get to choose the compiler version, the compiler version chooses you, based on your Unicode level. By the way, indentation is a no-brainer in Legacy: Each line starts with the line number, that is enough indentation already.
If you want to deploy a Legacy project to a production server, you need, by the rules above, the exact machine with a perfect replication of all installations for development. Because this is a painful endeavour, most developers have adopted the best practice of “one machine per project” and develop directly on the production server. Most of the time, this is a surprisingly powerful machine, making programming even more faster (remember, the goal is to produce the most amount of code in the least time). It also shortens the delivery pipeline length and facilitates communication between business and development departments, even if not of the pleasant type.
A curiosity that novice Legacy programmers often don’t grok at first is the IMPOSE keyword. It is a variant of the IMPORT functionality of other languages, but doesn’t extend the capabilities of your code. Instead, it limits the ability of the developers in this project by the given imposition. A typical example would be the line
IMPOSE variable name length <= 3
That, as you can read in clear text, limits your variable names to three characters or less. You can often find Legacy code with variable names like “usr” instead of “user”, “pwd” instead of “password” and “idx” instead of “index”. They all follow the imposition above, increase your typing speed and speed up the compilation, which counts as a triple win.
So, if you want to impress your customer with huge amounts of important looking code and build a certain reputation among peers, Legacy might be your new favorite language. And if anybody calls your work result “legacy code” in the future, you should feel validated and proud.
A programming language for mission-critical software
Software written for high-stake contexts like flight control, medical supervision and power plant management needs to meet extreme requirements in regard of correctness, robustness and resilience. Most mainstream programming languages have reacted by providing additional complexity to address the situation. For example, the demand for correct software has lead to the rise of testing frameworks that introduce additional syntax and require additional source code that is, by definition, untested in itself.
This is the problem the inventors of “Untested” try to solve. By writing your code in “Untested”, you can forgo all the extra effort of trying to prove it right. Untested code is, by definition, good enough without test. Remember the definition of Michael Feathers?
To me, legacy code is simply code without tests.
Michael Feathers in his book “Working Effectively with Legacy Code”
If you are ok with “Legacy”, you probably also enjoy “Untested”. The language makes it impossible to write tests for your code, so you can fend off the demand for them more easily. Your boss cannot ask for things that are impossible to do.
One interesting way in which “Untested” wards off calls from test routines is to couple every statement with a side effect in the hardware (oftentimes the TRAP flag on the CPU is flipped). Most programmers in traditional languages find those lines not testable and try to factor them away in order to test the rest. Untested factors away the rest. You don’t need to feel guilty about your lacking test coverage – it’s a feature, not a bug.
If your boss asks if a certain module is thorougly tested, you can respond “yes” in good faith. It’s tested in the best manner possible with “Untested”. If you need to give an overview of your system, you can write “Untested” beside every module and your reviewers will accept it as accurate.
Oh, the problem of long and tedious code reviews are taken into account, too. Because “Untested” code is just “Legacy” code (see Michael Feather’s definition above), it is impossible to read and understand with the exception of the developer machine (aka production server). If a thing is impossible to do, why even start trying? This will give you more time to produce “Untested” code.
And if problems arise in production? Well, you are already on the machine, so you can just hotfix it. Nobody can blame you, you’ve stated again and again that it’s untested code.
By the way: “Hotfix” is another promising programming language worth speaking about, but that would go beyond the scope of this blog entry. Might add it later, though.
A programming language for non-programmers
The central tragedy of software development is that the people that CAN program don’t know what they SHOULD program and the people that know exactly what SHOULD be programmed CANNOT do it. The latter group is mostly managers and people with million-dollar ideas.
The new kid on the programming language block tries to solve this problem by utilizing state-of-the-art artificial intelligence in the compiler AND the runtime. We are talking, of course, about “Straightforward”. It’s a programming language with a natural syntax that’s so easy and lenient, you can call it, well – you probably get the joke by now.
Remember the last time a stunned manager tried to explain the new feature to you and, when you came up with an estimate encompassing weeks for the implementation, shouted out “but it’s straightforward!”. He talked about his preferred programming language and you probably misunderstood him again.
“Straightforward” is so popular with the business folks because the compiler is in the “do what I mean” category of compilers. By using natural language recognition, it infers your most probable meaning of the code, looks it up on the internet and translates it into machine code. The first versions used sites like stackoverflow.com for the translation step, but that didn’t work out, because the site is filled by developers, not business people. Newer versions just access the cloud and find the answer there.
The machine code of “Straightforward” is not actual binary code, but an intermediate representation, much like Java’s bytecode, but for non-technical concepts. Because these concepts are subject of interpretation and the zeitgeist, they are really interpreted again at execution time by another artificial intelligence. This approach might be a bit demanding with processing power, but that’s just a financial problem. The big advantage is that code like “Make the colors more lively!” is both compilable and executable and yields the correct results regarding the current fashion every time. Your color scheme doesn’t age as fast or virtually not at all with this straightforward code.
The only problem that prohibits widespread adoption of “Straightforward” in the business right now is the unsolved equation:
Do what I mean != Do what I want
This is a fundamental theoretical problem in the field of management, much like P = NP in computer science. The race has already started, whoever solves his equation first gets the prize. It is rumored that quantum computing is the key to both. But I suspect that if quantum computing is available for everyday use, other programming languages like “ASAP” will take over the market.
Your turn
I hope this blog post has entertained (and maybe inspired) you. Now, it’s your turn. What is the programming language you always wanted to use? Be silly, be creative, be vocal. Write a comment below and tell us!
In Part 1, I explained how algebra can shed some light on a quite restricted class of react-apps. Today, I will lift one of the restrictions. This step needs a new kind of algebraic structure:
Categories
Category theory is a large branch of pure mathematics, with many facets and applications. Most of the latter are internal to pure mathematics. Since I have a very special application in mind, I will give you a definition which is less general than the most common ones.
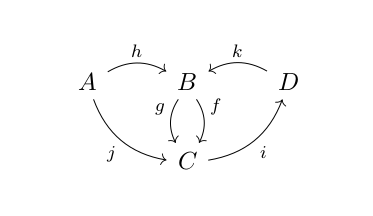
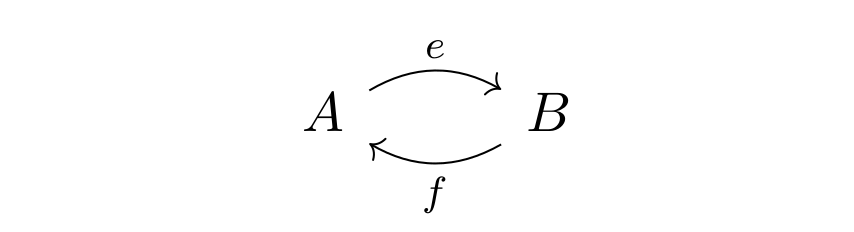
Categories can be thought of as generalized monoids. At the same time, a Category is a labelled, directed multigraph with some extra structure. Here is a picture of a labelled directed multigraph – its nodes are labelled with upper case letters and its edges are labelled with lower case letters:
If such a graph happens to be a category, the nodes are called objects and the edges morphisms. The idea is, that the objects are changed or morphed into other objects by the morphisms. We will write for a morphism from object to object .
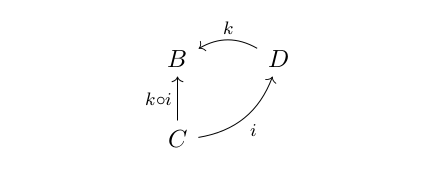
But I said something about extra structure and that categories generalize monoids. This extra structure is essentially a monoid structure on the morphisms of a category, except that there is a unit for each object called identity and the operation “” can only be applied to morphisms, if they form “a line”. For example, if we have morphisms like k and i in the picture below, in a category, there will be a new morphism ““:
Note that “” is on the right in “” but it is the first morphism if you follow the direction indicated by the arrows. This comes from function composition in mathematics, which suffers from the same weirdness by some historical accident. For now that just means that chains of morphisms have to be read from right to left to make sense of them.
For the indentities and the operation ““, we can ask for the same laws to hold as in a monoid, which will complete the definition of a category:
Definition (not as general as it could be…)
A category consists of the following data:
A set of objects A,B,…
A set of morphisms
An operation “” which for all (consecutive) pairs of morphisms and returns a morphism
For any object a morphism
Such that the following laws hold:
“ ” is associative: For all morphisms , and , we have:
The identities are left and right neutral: For all morphisms we have:
Examples
Before we go to our example of interest, let us look at some examples:
Any monoid is a category with one object O and for each element m of the monoid a morphism . “” is defined to be .
The graph below can be extended to a category by adding the morhpisms and an identity for and . The operation “” is defined as juxtaposition, where we treat the identities as empty sequences. So for example, is .
More generally: Let be a labelled directed graph with edges and nodes . Then there is a category with objects and morphisms all sequences of consectutive edges – including the empty sequence for any node.
Action Categories
So let’s generalize Part 1 with our new tool. Our new scope are react-apps, which have actions without parameters, but now, action can not neccessarily be applied in any order. If an action can be fired, may now depend on the state of the app.
The smallest example I can think of, where we can see whats new, is an app with two states, let’s call them ON and OFF and two actions, let’s say SWITCH_ON and SWITCH_OFF:
Let us also say, that the action SWITCH_ON can only be fired in state OFF and SWITCH_OFF only in state ON. The category for that graph has as its morphims the possible sequences of actions. Now, if we follow the path of part 1, the obvious next step is to say that SWITCH_ON after SWITCH_OFF (and the other way around) is the same as the empty action-sequence — which leads us to…
Quotients
We made a pretty hefty generalization from monoids to categories, but the theory for quotients remains essentially the same. As we defined equivalence relations on the elements of a monoid, we can define equivalence relations on the morphisms of a category. As last time, this is problematic in general, but turns out to just work if we replace sequences of morphisms in the action category with matching source and target.
So in the example above, it is ok to say that SWITCH_ON SWITCH_OFF is the empty sequence on ON and SWITCH_OFF SWITCH_ON is the empty sequence on OFF (keep in mind that the first action to be executed is on the right). Then any action sequence can be reduced to simply SWITCH_ON, SWITCH_OFF or an empty sequence (not the empty sequence, because we have two of them with different source and target). And in this case, the quotient category will be what we drew above, but as a category.
Of course, this is not an example where any high-powered math is needed to get any insights. So far, these posts where just about understanding how the math works. For the next part of this series, my plan is to show how existing tools can be used to calculate larger examples.
As this weird year, 2020, comes to a close, I noticed that I am still using the preprocessor in my C++ programs. And not just for #includes which might, at last, slowly fade away with C++20’s modules. The preprocessor’s got a pretty bad rep, and new C++ programmers are usually taught to stay as far away as possible. Justifiably so – some things, like the dreaded X-Macros really should go the way of the dinosaurs.
But there are still some good uses left in the thing, and here’s my top 3 of those:
0. Commenting out big-chunks of code
I’ve often seen people comment out big parts of code with block comments: /* this is not active */. However, that will only work as long as the code does not contain any other block comments, let alone a stray */ in a string. A great alternative is to use the preprocessor:
#if 0
auto i_do_not_want_to_compile_this() -> auto
{
std::vector<std::deque<std::mutex>> baz{};
return baz;
}
#endif
This can easiely by wrapped multiple times around bigger parts of code, which is very helpful when refactoring large chunks of legacy code. It can very easiely be toggled on and off while in this state. And the IDE will usually still show a dimmed version of syntax highlighting in the disabled region.
Some parts of aspects of programs can be “cross-cutting”, which means they cannot easiely be separated from the rest of the code-base by putting them in a separate module. The most prominent example is probably logging. While you can typically modularize the actual implementation, the actual log calls will be all over your code. Another of those concerns is “profiling”. This is also something that you typically want to take out of your application when deploying it, because users will rarely profile the end-product. Again, the preprocessor comes to the rescue. For example, in the excellent Optick, most of the code you insert is actually macros that can be completely eliminated with a simple compile-time switch. Consider this “tag” that add some additional metric to your profile:
OPTICK_TAG("CoolMetric", compute_cool_metric());
When Optick is turned off via the aforementioned compile-time switch, compute_cool_metric() is never called. The call is not even compiled. Just turning Optick off will completely remove it from your source. Now this can be potentially dangerous, if the function has a side effect, but you wouldn’t do that anyways, would you?
2. Making forward declarations more visible
Presumably owing to its history as a continuously-evolved language, C++ has a very limited set of reserved keywords, often avoiding to introduce keywords to not interfere with any working software out there. Do not get me wrong, that is a great reason. But because of this, some language constructs can sometimes be a bit cryptic, for example forward declarations: class will_be_defined;. If you ever worked with a big, old or big and old code-base with lots of those, you probably know that maintaining them can be a bit of a chore and prone to error. So I think it is a great idea to at least make them more visible with your own macro “KEYWORD”:
#define FORWARD_DECL(x) class x
FORWARD_DECL(will_be_defined);
That FORWARD_DECL immediatly stands out visually and helps me keep track of those subtle declarations.
Internationalisation, or i18n for short, is the process of making the user interface of a program ready for translation into multiple languages. This usually means to factor out texts from the program source code into separate files, often called translation bundles. These files have a key-value structure. The program code then only refers to keys that are resolved into the actual texts from the translation bundle for the selected target language.
Here’s a simple example of two translation bundles, one for English and one for German:
# translations_en.properties
quit_confirm_message=Do you really want to quit?
yes_option=Yes
no_option=No
# translations_de.properties
quit_confirm_message=Wollen Sie die Anwendung wirklich beenden?
yes_option=Ja
no_option=Nein
The actual source code might look like this:
var answer = showDialog(
t("quit_confirm_message"),
t("yes_option"),
t("no_option")
);
Here the function t looks up the key in the currently active translation bundle and returns the translated message as a string.
How not to do it
Last month I discovered an amusing attempt at internationalisation in a third-party code base. It looked similar to this:
"An article is available."
"An article is not available."
… or in German:
"Ein Artikel ist verfügbar."
"Ein Artikel ist nicht verfügbar."
Why is this a clumsy attempt at internationalisation?
Because it uses single words as translation units, and it relies on the fact that English and German have the same sentence structure in this particular case. In general, of course, languages do not have the same sentence structure, not even related languages like English and German.
The author of the code also introduced separate translation keys for “a” and “an”. The German translation for both keys was “ein”. The author was lucky so far that all texts with “a” or “an” in this particular program translated to “ein” in German, not “eine”, “einen”, “einem”, “einer”, or “eines”.
How to do it
So what would be the correct way to do it? The internationalisation should have looked like this:
# translations_en.properties
article_available=An article is available.
article_not_available=An article is not available.
# translations_de.properties
article_available=Ein Artikel ist verfügbar.
article_not_available=Ein Artikel ist nicht verfügbar.
available ? t("article_available")
: t("article_not_available")
By using whole phrases and sentences as translation units the translations into various languages have the freedom to use their own word orders and grammatical structures.
We are using continuous integration (CI) at the Softwareschneiderei for many years now. Our CI platform of choice is historically Jenkins which was called Hudson back in the day.
Things moved on since then and the integration with GitLab got a lot better with the advent of multibranch pipeline jobs. This kind of job allows you to automatically build branches and merge requests within the same job and keep the builds separate.
Another cool feature of Jenkins is the job configuration as code, defined in Jenkinsfile and used in pipeline jobs. That way it is easy to create and maintain a job configuration alongside your project’s source code inside your repository. No need anymore to click through pages of web UIs to configure your job. That way you also get the complete job configuration change history as additional benefits.
I prefer using scripted instead of declarative pipelines for Jenkinsfiles because they give me more control, freedom and power. But like always, this power and flexiblity comes at a price…
Sending out build notifications
In my case I wanted to always send out build notification regardless of the job result. This is quite easy if you have plugins like the Mattermost Notification Plugin or one of the mail plugins. Since our pipeline script consists of Groovy code this seems quite straightforward: Put the notification code into a try-finally-block:
node {
try {
stage ('Checkout and build') {
checkout scm
// Do something to build our project
}
// Maybe some additional stages like testing, code-analysis, packaging and deployment
} finally {
stage ('Notify') {
mattermostSend "${env.JOB_NAME} - ${currentBuild.displayName} finished with Status [${currentBuild.currentResult}] (<${env.BUILD_URL}|Open>)"
}
}
}
Unfortunately, this pipeline script will always return SUCCESS as the build result! Even if someone aborts the job execution or a stage in the try-block fails…
Managing build status
So the seasoned programmer probably already knows the fix: Setting the build result in appropriate catch-blocks:
node {
try {
stage ('Checkout and build') {
checkout scm
// Do something to build our project
}
// Maybe some additional stages like testing, code-analysis, packaging and deployment
} catch (Exception e) {
if (e in org.jenkinsci.plugins.workflow.steps.FlowInterruptedException) {
currentBuild.result = 'ABORTED'
} else {
echo "Exception: ${e.class}, message: ${e.message}"
currentBuild.result = 'FAILURE'
}
} finally {
stage ('Notify') {
mattermostSend "${env.JOB_NAME} - ${currentBuild.displayName} finished with Status [${currentBuild.currentResult}] (<${env.BUILD_URL}|Open>)"
}
}
}
You can control the granularity and the exceptions thrown by your build steps at will and implement exactly the status reporting that you want. The available statuses are defined in hudson.model.Result, so feel free to realize your own build status management to best fit your project.
This blog post does not contain big insights. It’s just the story of the very first days of our company which happens to celebrate its 20th anniversary this month. And because most stories begins a lot earlier than when the narrator begins to tell them, I’ll try to tell this one from the start.
It starts with an eight-year old boy that has access to his very first personal computer, a Tandon 8088 with 8 MHz. Just to put this glorified pocket calculator in today’s perspective: A basic arduino board has more power. But back in the days, this personal computer was a magical tool that could act as all kinds of things, including a gaming machine. One of the first games on this machine was Pac-Man, in 80×25 character ASCII “graphics” and without any scoreboard or competitive element. It was strictly single player and the computer-controlled ghosts acted strictly by their algorithms, so it became a repetitive chore rather soon. The boy would play the usual route, add some new steps at the end and watch the ghosts react. After some time, the boy could predict the ghosts’ reactions and plan the new steps with accuracy, clearing level after level. The ghosts never adapted.
By the age of twelve, the boy knew that he would become a “computer engineer”. Every occupational counselor (two in total) advised against this decision, not because it was bad, but because the counselors didn’t know anything about the profession. But the boy sticked to his decision and began his studies in computer science immediately after school was over. This was in 1997, when the internet still made sounds and you could ruin an hour-long download just by picking up the phone.
The boy, now a young man far from home, studied basic computer science for six month until the semester break arrived. Most other students returned home, but he stayed and teamed up with other students still on campus. They planned to program a computer game. A pac-man game, but with multiplayer abilities. One team would be “the players” or “pac-men”, the other team would be “the ghosts”. If somehow there wouldn’t be a dozen human players in front of the keyboard, the computer would control the remaining avatars. Game controls worked with split keyboard and – planned for later versions – over the network.
The only way the students knew how to organize the project was to transform one room into a computer-ridden workshop and hack away. Every horizontal platform in the room became a desk. The project should happen in a span of 24 hours. Today, this would be called a “game jam“. After 24 hours, all we had was a map. No game, no players, nothing exciting – just the future game’s map. But we agreed to continue working until the game is finished.
It took the three students a whole week. A week without much sleep, slippy food and lots of source code. Because we didn’t know about version control yet (nobody told us and we didn’t set up a local network, anyway), we had to structure the code in way that would allow us to work on different parts without collisions and transfer them from computer to computer using floppy disks. We had to maintain a list of files that were modified and did so on a central whiteboard that the young man had bought at the beginning of his studies. This whiteboard became the planning area where we would keep track of our modifications, tasks and concepts, including the stereotypical post-it notes. In hindsight, you could call it a chaotic story board. Without the whiteboard, we probably would have failed.
But after the week, the game was finished. We had developed a multiplayer pac-man in Java, complete with graphics, sounds and multi-threading. It was playable! We named it “Hubert 2D”, a reference to both “Duke Nukem 3D”, a very 90s game, and to one of our most famous fellow students. The game was blazingly fast – so fast, in fact, that you often lost track of your avatar. The unofficial motto of the game turned out to be “where am i?”. It was crammed with features. Just a Pac-Man where you could gobble up little pills and evade the ghosts was not enough for us. First, there was Hubert, the boss ghost. He appeared randomly and could not be player-controlled. He had a rocket launcher. If you defeated Hubert, you could grab the rocket launcher and, well, launch rockets. How can you defeat a rocket-launching ghost in Pac-Man? With your chainsaw, evidently. Players could pick up chainsaws to defend themselves against the ghosts. Ghosts could pick up energy shields to defend themselves against the chainsaws. Players could place mines to blow up ghosts that didn’t pay attention. Ghosts could place bombs to create new passageways to evade the mines or blow up the players. Sheep wandered around cluelessly, being blown up by mines, bombs, chainsaws or rockets and generally acting like a mobile roadblock. Teleporters added to the confusion by instantly teleporting you to either another teleporter or a random place on the map (leading to the infamous “where am i?”). But above all, you could poison and heal other avatars with various potions. Taking everything into account, this wasn’t Pac-Man anymore. This was team deathmatch that lasted until all the pills on the map were gobbled up accidentally.
Two funny moments during development and testing (aka playing) will always stay in my memory:
You could poison an avatar, but also heal it with medicine. Being healed was indicated by an “hallelujah” sound effect. But, because every new avatar on the map would be created in the “healed” state, we had a serious “hallelujah” epidemic going on. It took us way longer than it should have to connect the dots and eliminate the sound effect during creation.
Every avatar on the map moved with the same speed. Some avatars like bombs or mines decided not to move at all, others like sheep and Hubert only moved sometimes, but rockets flew twice as fast. So it was not possible to outrun a rocket. Because of this imbalance in power, we deemed the Hubert boss to be invincible in close combat. You could not walk up to him without facing a rocket that reached you at least a tile before you could employ your chainsaw. We were proven wrong, when one player used an energy shield in combination with a chainsaw and a hallway corner to sneak up on Hubert, neutralize the first rocket with the energy shield and defeat Hubert with the chainsaw before the second rocket could be fired. Because we thought that Hubert would be invincible, this move didn’t gain any in-game points. But the moment turned legendary immediately.
This week of intensive teamwork, combined with the result of an actual game, provided us with the trust and groundworks for future collaboration. So it was no wonder that, just a few semesters later, we came up with the idea of selling this collaboration ability in the form of a software development company. We were more knowledgeable, better equipped and had trained working together multiple times. What better times than now?
So we founded our company, the Softwareschneiderei (“software tailoring”) in late 2000, twenty years ago. Because we really meant it to be earnest, we invested the money to create a limited liability company and had to learn all the topics and obligations that follow such a creation in a very short time. We were still studying at university, but working for our own company, in a rented office, in every free minute. Our primary goal was to finish our studies with a degree. Our secondary goal was to let the company survive long enough to make it the primary goal after graduation. The plan worked out and here we are, twenty years later.
The statistics says that only one out of ten companies survives their first five years. Even after that, keeping a company afloat is not sunshine sailing. Somehow, we made it. Despite all our mistakes and misconceptions (and there were many, most on a more serious level than deeming Hubert to be invincible), we developed our company in a way that provides benefit for our customers and profit for our employees.
And in a corner of my desk drawer, there is still a 3,5″ floppy disk labelled “Hubert 2D”. Because that’s the source code that got this company started, 23 years ago.
Indeed, web development is kind of peculiar. On the one hand, there‘s seldom a field in which new technologies overturn each other at that pace, creating very exciting opportunities ranging from quickly sketching out proof-of-concepts to the efficient construction of real-world applications. On the other hand, there is this strange air of browser dependency and with any new technology one acquires, there‘s always the question of whether this is just some temporary fashion or here to stay.
Which is why it hapens, that one would like to quickly scaffold a web application on the base of React and its ecosystem, but has the requirement that the customer is – either voluntarily or forced by higher powers – using some legacy browser like Internet Explorer 11, for which Microsoft has recently announced its end of life support for 30th November this year. Which doesn’t sound nice for the… *searching quickly* … 5% of desktop/laptop users that still use this old horse, but then again, how long can you cling to an outdated thing?
For the daily life of a web developer, his mind full of peculiarities that the evolution of the ECMAScript standard which basically is JavaScript, there is the practical helper of caniuse.com, telling you for every item of your code you want to know about, which browser / device has support and which doesn’t.
But what about whole frameworks? When I recently had my quest for a IE11-comptabile React app, I already feared that at every corner, I needed to double-check all my doing, especially given that for the development itself, one is certainly advised to instead use one of the browsers that come with a quite some helpful developer tools, like extensions for React, Redux, etc. — but also the features in the built-in Console, where it makes your life a lot easier whether you can just log a certain state as a string of “[Object object]” or a fully interactive display of object properties. Sorry IE11, there are reasons why you have to go.
But actually, then, I figured, that my request is maybe not that far outside the range of rather widespread use cases. Thus, the chance that someone already tried to tackle the problem, aren’t so hopeless. And so this works pretty straightforward:
Install “react-app-polyfill”, e.g. via npm:
npm install react-app-polyfill
At the very top of your index.js, add for good measure:
Include “IE 11” (with quotes) in your package.json under the “browserlist” as a new entry under “production” and “development”
That should do it. There are people on the internet that advise removing the “node_modules/.cache” directory when doing this in an existing project.
The term of a polyfill is actually derived from some kind of putty, which is actually a nice picture. It’s all about allowing a developer to use accustomed features while maintaining the actual production environment.
Another very useful polyfill in this undertaking was…
// install
npm install --save-dev @babel/plugin-transform-arrow-functions
// then add to the "babel" > "plugins" config array:
"babel": {
"plugins": [
"@babel/plugin-transform-arrow-functions"
]
}
… as I find the new-fashioned arrow function notation quite useful.
So, this seems to bridge (most of) the worries one encounters in this web dev world where use cases span eons of technology evolution. Now, do you know any more useful polyfills that make your life easier?
When I learned to use the react framework, I always had the feeling that it is written in a very mathy way. Since simple googling did not give me any hints if this was a consideration in the design, I thought it might be worth sharing my thoughts on that. I should mention that I am sure others have made the same observations, but it might help algebraist to understand react faster and mathy computer scientiests to remember some algebra.
Free monoids
In abstract algebra, a monoid is a set M together with a binary operation “” satisfying these two laws:
There is a neutral element “e”, such that:
The operation is associative, i.e.
Here are some examples:
Any set with exactly one element together with the unique choice of operation on it.
The natural numbers with addition.
The one-based natural numbers with multiplication.
The Integers with addition.
For any set M, the set of maps from M to M is a monoid with composition of maps.
For any set A, we can construct the set List(A), consisting of all finite lists of elements of A. List(A) is a monoid with concatenation of lists. We will denote lists like this:
Monoids of the form List(A) are called free. With “of the form” I mean that the elements of the sets can be renamed so that sets and operations are the same. For example, the monoid with addition and List({1}) are of the same form, witnessed by the following renaming scheme:
— so addition and appending lists are the same operation under this identification.
With the exception of , the integers and the monoid of maps on a set, all of the examples above are free monoids. There is also a nice abstract definition of “free”, but for the purpose at hand to describe a special kind of monoid, it is good enough to say, that a monoid M is free, if there is a set A such that M is of the form List(A).
Action monoids
A react-app (and by that I really mean a react+redux app) has a set of actions. An action always has a type, which is usally a string and a possibly empty list of arguments.
Let us stick to a simple app for now, where each action just has a type and nothing else. And let us further assume, that actions can appear in arbirtrary sequences. That means any action can be fired in any state. The latter simplification will keep us clear from more advanced algebra for now.
For a react-app, sequences of actions form a free monoid. Let us look at a simple example: Suppose our app is a counter which starts with “0” and has an increment (I) and decrement (D) action. Then the sequences of action can be represented by strings like
ID, IIDID, DDD, IDI, …
which form a free monoid with juxtaposition of strings. I have to admit, so far this is not very helpful for a practitioner – but I am pretty sure the next step has at least some potential to help in a complicated situation:
Quotients
Quotients of sets by an equivalence relation are a very basic tool of modern math. For a monoid, it is not clear if a quotient of its underlying set will still be a monoid with the “same” operations.
Let us look at an example, where everything goes well. In the example from above, the counter should show the same integer if we decrement and then increment (or the other way around). So we could say that the two action sequences
ID and
DI
do really nothing and should be considered equivalent to the empty action sequence. So let’s say that any sequence of actions is equivalent to the same sequence with any occurence of “DI” or “ID” deleted. So for example we get:
IIDIIDD I
With this rule, we can reduce any sequence to an equivalent one that is a sequence of Is, a sequence of Ds or empty. So the quotient monoid can be identified with the integers (in two different ways, but that’s ok) and addition corresponds to juxtaposition of action sequences.
The point of this example and the moral of this post is, that we can take a syntactic description (the monoid of action sequences), which is easy to derive from the source code and look at a quotient of the action monoid by a reasonable relation to arrive at some algebraic structure which has a lot to do with the semantic of the app.
So the question remains, if this works just well for an example or if we have a general recipe.
Here is a problem in the general situation: Let be elements of a monoid with operation “” and be an equivalence relation such that is identified with . Then, denoting equivalence classes with it is not clear if should be defined to be or .
Fortunately problems like that disappear for free monoids like our action monoid and equivalence relations constructed in a specific way. As you can see on wikipedia, it is always ok to take the equivalence relation generated by the same kind of identifications we made above: Pick some pairs of sequences which are known “to do the same” from a semantic point of view (like “ID” and “DI” did the same as the empty sequence) and declare sequences to be equivalent, if they arise by replacing sequences known to be the same.
So the approach is that general: It works for apps, where actions do not have parameters and can be fired in any order and for equivalence relations generated by defining finitely many action sequences to do the same. The “any order” is a real restriction, but this post also has a “Part 1” in the title…
Recently, I was experiencing a strange crash that I traced to a piece of C++ code looking more or less like this:
template <class T>
class container
{
public:
std::vector<T> values_;
T default_;
T const& get() const
{
if (values_.empty())
return default_;
return values.front();
}
};
This was crashing when calling get(), with a non-empty values_ member. It looks fairly innocent. And it ran in production for a couple of years already. So what changed?
I had, in fact, never instanciated this template with T = bool before. And that was causing the crash, while still compiling without any errors. Now if you’re a little versed in the C++ standard library you might know that std::vector is a special snowflake indeed. In an effort to save space, and, I suspect, prove the usefulness of template specializations, it is not really a “normal” container holding bool values. Instead, it holds some type of integers and packs each pseudo-bool into one of their bits. The consequence is that the accessor functions like operator[], front() and back() cannot return a reference to a bool. Instead, they return a “proxy” object that supports assignment to and from a bool.
Back to the get() function: it tries to return a reference to a bool. Of course, that bool doesn’t really exist except as a temporary, and so this results in a dangling reference that causes a segmentation fault when used.
I suspect there could have been a warning about a dangling reference somewhere there. I have seen clang-tidy especially report things like this (with a few false positives too), but it did not show up for me. To fix it, I am now just returning a bool instead of a bool const& for T = bool. A special case in my case to work around a special case in std::vector.

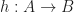 for a morphism from object
for a morphism from object  to object
to object  .
. ” can only be applied to morphisms, if they form “a line”. For example, if we have morphisms like k and i in the picture below, in a category, there will be a new morphism “
” can only be applied to morphisms, if they form “a line”. For example, if we have morphisms like k and i in the picture below, in a category, there will be a new morphism “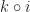 “:
“:
 ” is on the right in “
” is on the right in “
 and
and  returns a morphism
returns a morphism 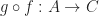

 ,
, 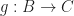 and
and  , we have:
, we have: 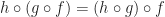
 we have:
we have: 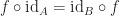
 . “
. “ ” is defined to be
” is defined to be 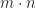 .
.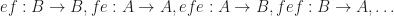 and an identity for
and an identity for 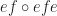 is
is  .
.
 be a labelled directed graph with edges
be a labelled directed graph with edges  and nodes
and nodes  . Then there is a category
. Then there is a category 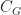 with objects
with objects 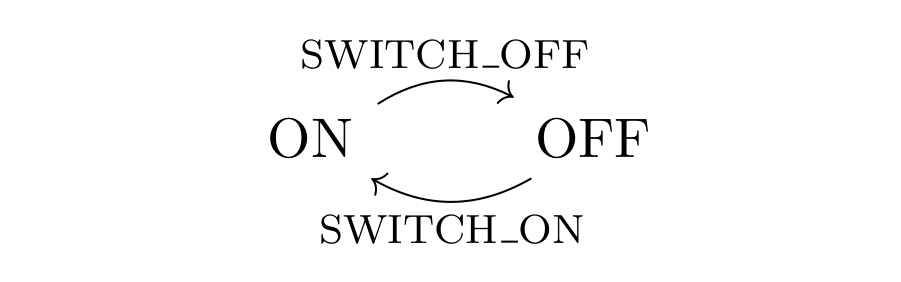
 ” satisfying these two laws:
” satisfying these two laws:

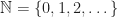 with addition.
with addition.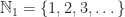 with multiplication.
with multiplication.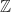 with addition.
with addition.![[1,2,3,\dots]](https://s0.wp.com/latex.php?latex=%5B1%2C2%2C3%2C%5Cdots%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 with addition and List({1}) are of the same form, witnessed by the following renaming scheme:
with addition and List({1}) are of the same form, witnessed by the following renaming scheme:![0 \mapsto []](https://s0.wp.com/latex.php?latex=0+%5Cmapsto+%5B%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![1 \mapsto [1]](https://s0.wp.com/latex.php?latex=1+%5Cmapsto+%5B1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![2 \mapsto [1,1]](https://s0.wp.com/latex.php?latex=2+%5Cmapsto+%5B1%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![3 \mapsto [1,1,1]](https://s0.wp.com/latex.php?latex=3+%5Cmapsto+%5B1%2C1%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

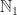 , the integers and the monoid of maps on a set, all of the examples above are free monoids. There is also a nice abstract definition of “free”, but for the purpose at hand to describe a special kind of monoid, it is good enough to say, that a monoid M is free, if there is a set A such that M is of the form List(A).
, the integers and the monoid of maps on a set, all of the examples above are free monoids. There is also a nice abstract definition of “free”, but for the purpose at hand to describe a special kind of monoid, it is good enough to say, that a monoid M is free, if there is a set A such that M is of the form List(A).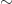 I
I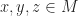 be elements of a monoid
be elements of a monoid  with operation “
with operation “ is identified with
is identified with 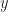 . Then, denoting equivalence classes with
. Then, denoting equivalence classes with ![[\_]](https://s0.wp.com/latex.php?latex=%5B%5C_%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) it is not clear if
it is not clear if ![[x] \cdot [y]](https://s0.wp.com/latex.php?latex=%5Bx%5D+%5Ccdot+%5By%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) should be defined to be
should be defined to be ![[x\cdot z]](https://s0.wp.com/latex.php?latex=%5Bx%5Ccdot+z%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) or
or ![[y\cdot z]](https://s0.wp.com/latex.php?latex=%5By%5Ccdot+z%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. 