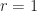A common way to draw circles with any kind of vector graphics API is by approximating it with a regular polygon, e.g. as a regular polygon with 32 sides. The problem with this approach is that it might look good in one resolution, but crude in another, as the approximation becomes more visible. So how do you pick the right number of sides for the job? For that, let’s look at the error that this approximation has.
A whole bunch of math
I define the ‘error’ of the approximation as the maximum difference between the ideal circle shape and the approximation. In other words, it’s the difference of the inner radius and the outer radius of the regular polygon. Conveniently, with a step angle the inner radius is just the outer radius multiplied by the cosine of half of that: . So the error is . I find it convenient to use relative error for the following, and set :
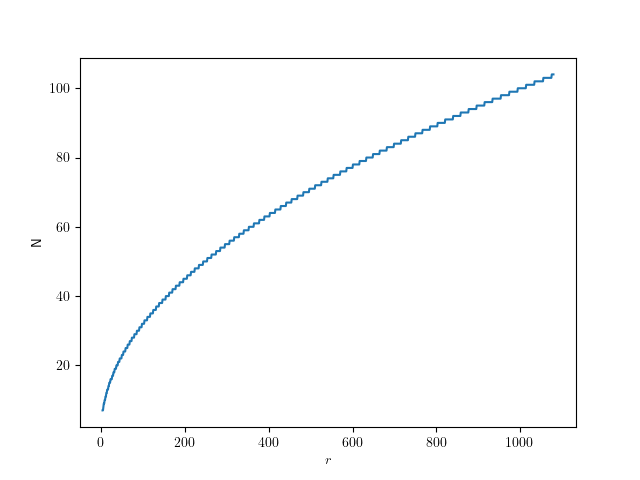
The following plot shows that value for going from 4 to 256:
As you can see, this looks hyperbolic and the error falls off rather fast with an increasing number of subdivisions. This function lets use figure out the error for a given number of subdivisions, but what we really want is he inverse of that: Which number of subdivisions do we need for the error to be less than a given value. For example, assuming a 1080p screen, and a half-pixel error on a full-size () circle, that means we should aim for a relative error of . So we can solve the error equation above for N. Since the number of subdivisions should be an integer, we round it up:
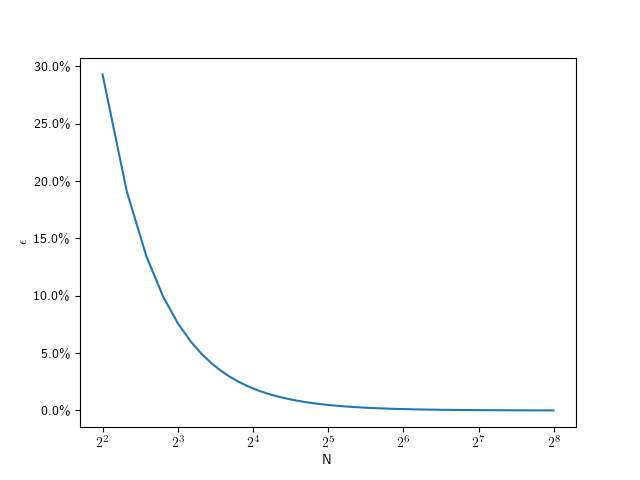
So for we need only 71 divisions. The following plot shows the number of subdivisions for error values from to :
Here are some specific values:
0.01%
223
0.1%
71
0.2%
50
0.4%
36
0.6%
29
0.8%
25
1.0%
23
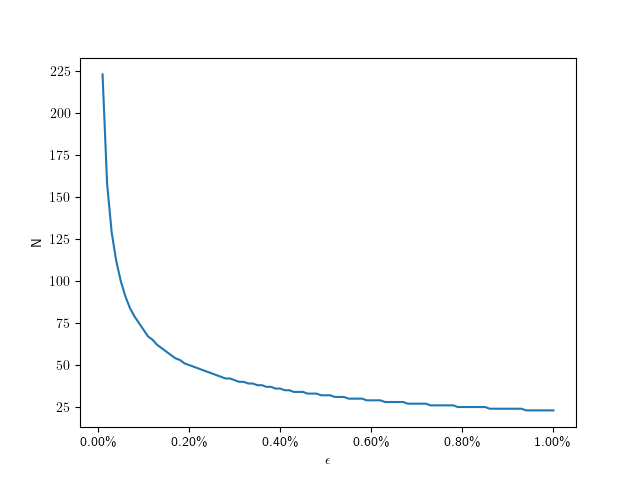
Assuming a fixed half-pixel error, we can plug in to get:
The following graph shows that function for radii up to full-size QHD circles:
Give me code
Here’s the corresponding code in C++, if you just want to figure out the number of segments for a given radius:
If you’ve worked with PostgreSQL and dealt with things like full-text search, arrays, or JSON data, you might have heard about GIN indexes. But what exactly are they, and why are they useful?
GIN stands for Generalized Inverted Index. Most indexes (like the default B-tree index) work best when there’s one clear value per row – like a number or a name. But sometimes, a single column can hold many values. Think of a column that stores a list of tags, words in a document, or key-value data in JSON. That’s where GIN comes in.
Let’s walk through a few examples to see how GIN indexes work and why they’re helpful.
Full-text search example
Suppose you have a table of articles:
CREATE TABLE articles (
id serial PRIMARY KEY,
title text,
body text
);
You want to let users search the content of these articles. PostgreSQL has built-in support for full-text search, which works with a special data type called tsvector. To get started, you’d add a column to store this processed version of your article text:
ALTER TABLE articles ADD COLUMN tsv tsvector;
UPDATE articles SET tsv = to_tsvector('english', body);
Now, to speed up searches, you create a GIN index:
CREATE INDEX idx_articles_tsv ON articles USING GIN(tsv);
With that in place, you can search for articles quickly:
SELECT * FROM articles WHERE tsv @@ to_tsquery('tonic & water');
This finds all articles that contain both “tonic” and “water”, and thanks to the GIN index, it’s fast – even if you have thousands of articles.
Array example
GIN is also great for columns that store arrays. Let’s say you have a table of photos, and each photo can have several tags:
CREATE TABLE photos (
id serial PRIMARY KEY,
tags text[]
);
You want to find all photos tagged with “capybara”. You can create a GIN index on the tags column:
CREATE INDEX idx_photos_tags ON photos USING GIN(tags);
SELECT * FROM photos WHERE tags @> ARRAY['capybara'];
(The @> operator means “contains” or “is a superset of”.)
The index lets PostgreSQL find matching rows quickly, without scanning the entire table.
JSONB example
PostgreSQL’s jsonb type lets you store flexible key-value data. Imagine a table of users with extra info stored in a jsonb column:
CREATE TABLE users (
id serial PRIMARY KEY,
data jsonb
);
One row might store {"age": 42, "city": "Karlsruhe"}. To find all users from New York, you can use:
SELECT * FROM users WHERE data @> '{"city": "Karlsruhe"}';
And again, with a GIN index on the data column, this query becomes much faster:
CREATE INDEX idx_users_data ON users USING GIN(data);
Things to keep in mind
GIN indexes are very powerful, but they come with some tradeoffs. They’re slower to build and can make insert or update operations a bit heavier. So they’re best when you read (search) data often, but don’t write to the table constantly.
In short, GIN indexes are your friend when you’re dealing with columns that contain multiple values – like arrays, full-text data, or JSON. They let PostgreSQL break apart those values and build a fast lookup system. If your queries feel slow and you’re working with these kinds of columns, adding a GIN index might be exactly what you need.
Nowadays many of us are developing libraries, tools and applications somehow connected to the web. Often we provide APIs over HTTP(S) for frontends or other services or develop web apps using such services or backends.
As browsers become more and more picky HTTP is pretty much dead but for developers it is extremely convenient to avoid the hassle of certificates, keystores etc.
Luckily, there is a simple and free tool, that can help in several development scenarios: zrok.io
My most common ones are:
Allowing customers easy (temporary) access to your app in development
Developing SSO and other integrations that need publicly visible HTTPS endpoints
Collaborating with your distributed colleagues and allowing them to develop against your latest build on your machine
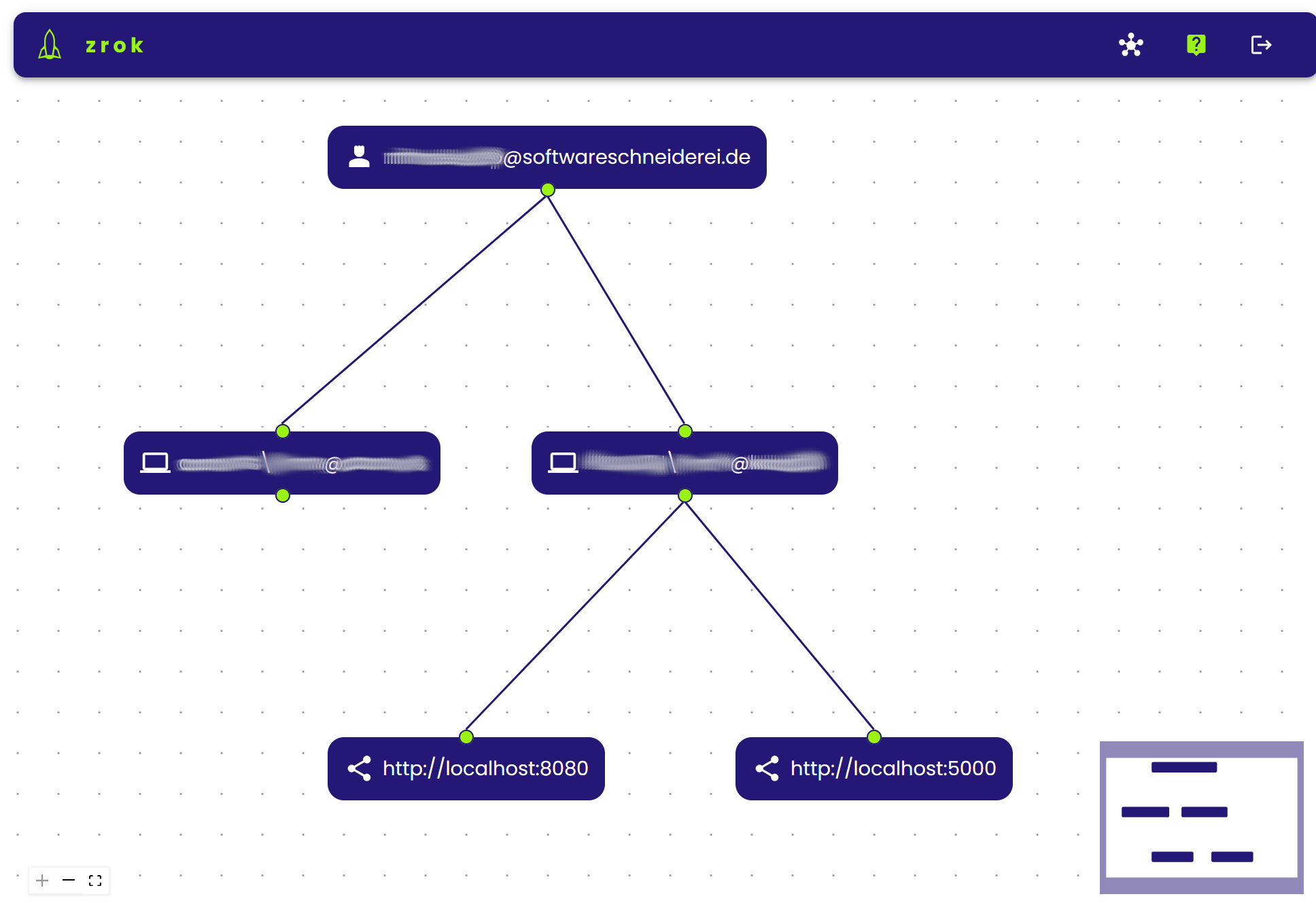
What is zrok?
For our use cases think of it as an simple, ad-hoc HTTPS-proxy transport-securing your services and exposing them publicly. For the other features and technical zero trust networking platform explanation head over to their site.
How to use zrok?
You only need a few steps to get zrok up and running. Even though their quick start explains the most important steps I will mention them here too:
Enable your local environment using your token with zrok enable <your_token>
After these steps your are ready to go and may share your local service running on http://localhost:8080 using zrok share public 8080.
Some practical advice and examples
If you want a stable URL for your service, use a reserved share instead of the default temporary one:
.\zrok.exe reserve public http://localhost:5000 --unique-name "mydevinstance"
.\zrok.exe share reserved mydevinstance
That way you get a stable endpoint over restarts which greatly reduces configuration burden in external services or communication with customers or colleagues. You can manage your shares on multiple machines online on https://api-v1.zrok.io:
Your service is then accessible under https://mydevinstance.share.zrok.io/ and you may monitor accesses in the terminal or on the webpage above.
Using zrok developers may continue to ignore HTTPS for their local development instances while still being able to expose them privately or publicly including transparent SSL support.
That way you can integrate easily with other services expecting secured public endpoint or collaborate with others transparently without VPNs, tunnels or other means.
I have a particular programming style regarding constructors in Java that often sparks curiosity and discussion. In this blog post, I want to note my part in these discussions down.
Let’s start with the simplest example possible: A class without anything. Let’s call it a thing:
public class Thing {
}
There is not much you can do with this Thing. You can instantiate it and then call methods that are present for every Object in Java:
Thing mine = new Thing();
System.out.println(
mine.hashCode()
);
This code tells us at least two things about the Thing class that aren’t immediately apparent:
It inherits methods from the Object class; therefore, it extends Object.
It has a constructor without any parameters, the “default constructor”.
If we were forced to write those two things in code, our class would look like this:
public class Thing extends Object {
public Thing() {
super();
}
}
That’s a lot of noise for essentially no signal/information. But I adopted one rule from it:
Rule 1: Every production class has at least one constructor explicitly written in code.
For me, this is the textual anchor to navigate my code. Because it is the only constructor (so far), every instantiation of the class needs to call it. If I use “Callers” in my IDE on it, I see all clients that use the class by name.
Every IDE has a workaround to see the callers of the constructor(s) without pointing at some piece of code. If you are familiar with such a feature, you might use it in favor of writing explicit constructors. But every IDE works out of the box with the explicit constructor, and that’s what I chose.
Record classes are syntactic sugar that don’t benefit from an explicit constructor that replaces the generated one. In fact, record classes use much of their appeal once you write constructors for them.
Anonymous inner types are oftentimes used in one place exclusively. If I need to see all their clients by using the IDE, my code is in a very problematic state, and an explicit constructor won’t help.
One thing that Rule 1 doesn’t cover is the first line of each constructor:
Rule 2: The first line of each constructor contains either a super() or a this() call.
The no-parameters call to the constructor of the superclass is done regardless of my code, but I prefer to see it in code. This is a visual cue to check Rule 3 without much effort:
Rule 3: Each class has only one constructor calling super().
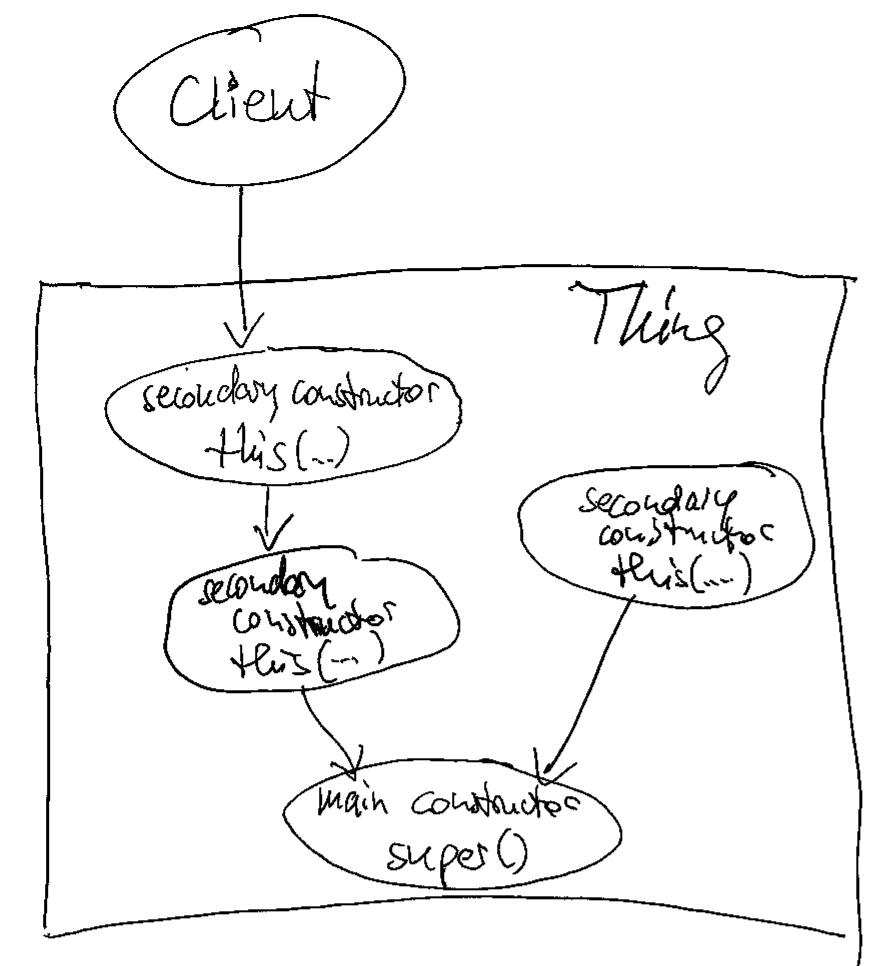
If you incorporate Rule 3 into your code, the instantiation process of your objects gets much cleaner and free from duplication. It means that if you only exhibit one constructor, it calls super() – with or without parameters. If you provide more than one constructor, they form a hierarchy: One constructor is the “main” or “core” constructor. It is the one that calls super(). All the other constructors are “secondary” or “intermediate” constructors. They use this() to call the main constructor or another secondary constructor that is an intermediate step towards the main constructor.
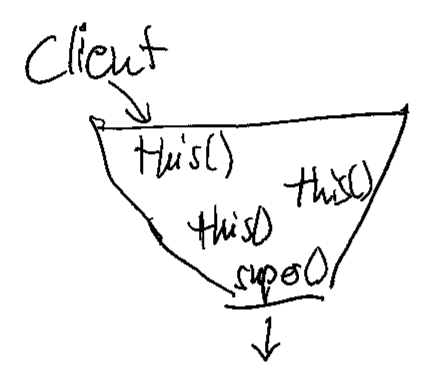
If you visualize this construct, it forms a funnel that directs all constructor calls into the main constructor. By listing its callers, you can see all clients of your class, even those that use secondary constructors. As soon as you have two super() calls in your class, you have two separate ways to construct objects from it. I came to find this possibility way more harmful than useful. There are usually better ways to solve the client’s problem with object instantiation than to introduce a major source of current or future duplication (and the divergent change code smell). If you are interested in some of them, leave a comment, and I will write a blog entry explaining some of them.
Back to the funnel:
if you don’t see the funnel yet, let me abstract the situation a bit more:
This is how it looks in source code:
public class Thing {
private final String name;
public Thing(int serialNumber) {
this(
"S/N " + serialNumber
);
}
public Thing(String name) {
super();
this.name = name;
}
}
I find this structure very helpful to navigate complex object construction code. But I also have a heuristic that the number of secondary constructors (by visually counting the this() calls) is proportional to the amount of head scratching and resistance to change that the class will induce.
As always, there are exceptions to the rule:
Some classes are just “more specific names” for the same concept. Custom exception types come to mind (see the code example below). It is ok to have several super() calls in these classes, as long as they are clearly free from additional complexity.
Enum types cannot have the super() call in the main constructor. I don’t write a comment as a placeholder; I trust that enum types are low-complexity classes with only a few private constructors and no shenanigans.
This is an example of a multi-super-call class:
public class BadRequest extends IOException {
public BadRequest(String message, Throwable cause) {
super(message, cause);
}
public BadRequest(String message) {
super(message);
}
}
It clearly does nothing more than represent a more specific IOException. There won’t be many reasons to change or even just look at this code.
I might implement a variation to my Rule 2 in the future, starting with Java 22: https://openjdk.org/jeps/447. I’m looking forward to incorporating the new possibilities into my habits!
As you’ve seen, my constructor code style tries to facilitate two things:
Navigation in the project code, with anchor points for IDE functionality.
Orientation in the class code with a standard structure for easier mental mapping.
It introduces boilerplate or cruft code, but only a low amount at specific places. This is the trade-off I’m willing to make.
What are your ideas about this? Leave us a comment!