
A few years back, we posted an article on how to get CMake, googletest and jenkins to play nicely with each other. Since then, Phil Nash’s catch testing library has emerged as arguably the most popular thing to write your C++ tests in. I’m going to show how to setup a small sample project that integrates catch2, CMake and Jenkins nicely.
Project structure
Here is the project structure we will be using in our example. It is a simple library that implements left-pad: A utility function to expand a string to a minimum length by adding a filler character to the left.
├── CMakeLists.txt
├── source
│ ├── CMakeLists.txt
│ ├── string_utils.cpp
│ └── string_utils.h
├── externals
│ └── catch2
│ └── catch.hpp
└── tests
├── CMakeLists.txt
├── main.cpp
└── string_utils.test.cpp
As you can see, the code is organized in three subfolders: source, externals and tests. source contains your production code. In a real world scenario, you’d probably have a couple of libraries and executables in additional subfolders in this folder.
The source folder
set(TARGET_NAME string_utils)
add_library(${TARGET_NAME}
string_utils.cpp
string_utils.h)
target_include_directories(${TARGET_NAME}
INTERFACE ./)
install(TARGETS ${TARGET_NAME}
ARCHIVE DESTINATION lib/)
The library is added to the install target because that’s what we typically do with our artifacts.
I use externals as a place for libraries that go into the projects VCS. In this case, that is just the catch2 single-header distribution.
The tests folder
I typically mirror the filename and path of the unit under test and add some extra tag, in this case the .test. You should really not need headers here. The corresponding CMakeLists.txt looks like this:
set(UNIT_TEST_LIST
string_utils)
foreach(NAME IN LISTS UNIT_TEST_LIST)
list(APPEND UNIT_TEST_SOURCE_LIST
${NAME}.test.cpp)
endforeach()
set(TARGET_NAME tests)
add_executable(${TARGET_NAME}
main.cpp
${UNIT_TEST_SOURCE_LIST})
target_link_libraries(${TARGET_NAME}
PUBLIC string_utils)
target_include_directories(${TARGET_NAME}
PUBLIC ../externals/catch2/)
add_test(
NAME ${TARGET_NAME}
COMMAND ${TARGET_NAME} -o report.xml -r junit)
The list and the loop help me to list the tests without duplicating the .test tag everywhere. Note that there’s also a main.cpp included which only defines the catch’s main function:
#define CATCH_CONFIG_MAIN #include <catch.hpp>
The add_test call at the bottom tells CTest (CMake’s bundled test-runner) how to run catch. The “-o” switch commands catch to direct its output to a file, report.xml. The “-r” switch sets the report mode to JUnit format. We will need both to integrate with Jenkins.
The top-level folder
The CMakeLists.txt in the top-level folder needs to call enable_testing() for our setup. Other than that, it just directs to the subfolders via add_subdirectory().
Jenkins
Now all that is needed is to setup Jenkins accordingly. Setup jenkins to get your code, add a “CMake Build” build-step. Hit “Add build tool invocation” and check “Use cmake” to let cmake handle the invocation of your build tool (e.g. make). You also specify the target here, which is typically “install” or “package” via the “–target” switch.

Now you add another step that runs the tests via CTest. Add another Build Step, this time “CMake/CPack/CTest Execution” and pick CTest. The one quirk with this is that it will let the build fail when CTest returns a non-zero exit code – which it does when any tests fail. Usually, you want the build to become unstable and not failed if that happens. Hence set “1-65535” in the “Ignore exit codes” input.

The final step is to let jenkins use the report.xml that we had CTest generate so it can generate the test result charts and tables. To do that, add the post-build action: “Publish JUnit test result report” and point it to tests/report.xml.
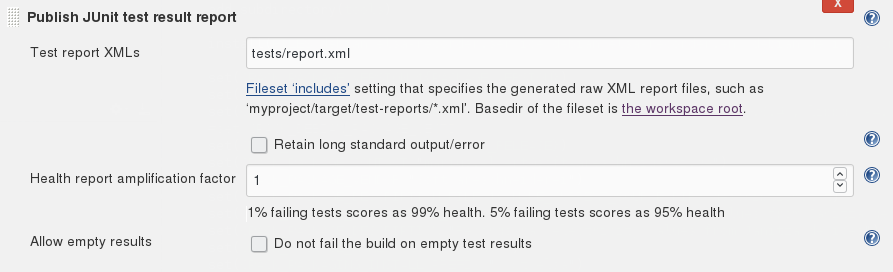
Done!
That’s it. Now you got your CI running nice catch tests. The code for this example is available on our github.
