entt will automatically call into on_construct and on_destroy.
People nowadays usually avoid linked lists because of all the pointer chasing required to actually use them. The pointer chasing is not the problem though, the non-locality is. If you make sure your nodes are all allocated in memory close to each other, there is hardly a penalty. entt will usually do this if nodes are also allocated close in time, which is often the case if you want to group things, so this works nicely in that regard, too. Feel free to use this code under CC0.
One problem I often have when dockerizing my C++ Jenkins CI projects is handling incremental builds, for both our own code and the dependencies. Starting builds from scratch can take tens of minutes, too long for my taste.
My build stack is usually conan as a dependency manager and CMake/Ninja for building. Conan will usually try to download precompiled dependencies, but often enough, those are not available for my specific combination of compiler settings and flags, so it’ll build them on demand with the --build=missing flag. That usually takes the bulk of the time needed for a full build. So it makes sense to keep the dependencies cached, once they are built. However, since we use Docker to setup the build environment, they are all lost by default.
Who Owns What?
The obvious solution is to mount a folder on the build host to keep the conan cache using the -v / –volume option for docker run. This can be done by setting the CONAN_HOME environment variable, and I usually use one cache per build folder, which seems like a good compromise between speed and isolation.
But that causes other problems: docker will create all the files for the user inside the container, which is root by default, creating a whole bunch of files that the CI host user cannot delete, e.g. when a branch gets deleted. This breaks the CI setup to a point where manual intervention is required. A somewhat simple clutch is the -u user:group option to docker run, which will execute the build with the given user. The problem I was having with that, however, was that this user did not have access to user-scoped tool installations like conan via pipx.
User-specific Images
My current strategy to deal with this is to inject the host CI user and group into the docker ‘builder’ image, and then do all the building in the container using that user, as if using the CI host user on the metal. The Dockerfile looks like this:
FROM gcc:14.1-bookworm
RUN DEBIAN_FRONTEND=noninteractive apt-get update && apt-get -y dist-upgrade
RUN DEBIAN_FRONTEND=noninteractive apt-get update && apt-get -y install \
After doing the user-independent setup, this declares two ARGs for retrieving the user and group IDs, and then sets up a user with those in the docker image, calling it hostuser:hostgroup internally. Note that the names will not leak out of the container, only the IDs do.
It installs conan via pipx as that user and makes sure it is in the PATH for the build later. This is the real advantage of passing the user into the image creation: user specific things can be installed!
In our Jenkinsfile, I build the image from that while injecting the current user via the –build-arg option:
docker build . --iidfile docker_image_id \
--build-arg HOST_USER_ID=`id -u` \
--build-arg HOST_GROUP_ID=`id -g`
This expects three folders to be mounted: /source_root for the sources/repository, /build_root for the out-of-source build, and /conan_home for the conan cache. Important: make sure these folders are created by the CI user before passing them to docker, or it will create them with the wrong owner. I’m only creating the latter two, since the first one is obviously created by Jenkins.
mkdir -p docker/build docker/conan
Once the folders are set up and the image is built, I run the actual build in a container via:
docker run --rm \
-v `pwd`:/source_root:ro \
-v `pwd`/docker/conan:/conan_home \
-v `pwd`/docker/build:/build_root \
`cat docker_image_id`
That should run the actual build and populate the conan cache. After that I extract the artifacts I need and remove the docker image and ID file with:
Back before C++11, the recommended way to customize the behavior of an algorithm was to write a functor-struct, e.g. a small struct overloading operator(). E.g. for sorting by a specific key:
Of course, the same logic could be implemented with a free function, but that was often advised against because it was harder for the compiler to inline. Either way, if you had to supply some context variables, you were stuck with the verbose functor struct anyways. And it made it even more verbose. Something like this was common:
That all changed, of course, when lambdas were added to the language, and you could write the same thing as:
auto indirect_less = [&](T const& lhs, T const& rhs)
{ return indirection[lhs.key] < indirection[rhs.key]; };
At least as long as the indirection std::vector<> is in the local scope. But what if you wanted to reuse some more complicated functors in different contexts? In that case, I often found myself reverting back to the old struct pattern. Until recently I discovered there’s a lot nicer way, and I ask myself how I missed that for so long: functor factories. E.g.
auto make_indirect_less(std::vector const& indirection) {
return [&](T const& lhs, T const& rhs) { /* ... */ };
}
Much better than the struct! This has been possible since C++14’s return type deduction, so a pretty long time. Still, I do not think I have come across this pattern before. What about you?
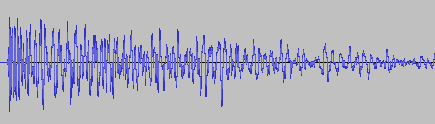
A couple of weeks ago, I asked my brother to test out my new game You Are Circle (please wishlist it and check out the demo, if that’s up your alley!) and among lots of other valuable feedback, he mentioned that the explosion sound effects had a weird click sound at the end that he could only hear with his headphones on. For those of you not familiar with audio signal processing, those click or pop sounds usually appear when the ‘curvy’ audio signal is abruptly cut off1. I did not notice it on my setup, but he has a lot of experience with audio mixing, so I trusted his hearing. Immediately, I looked at the source files in audacity:
They looked fine, really. The sound slowly fades out, which is the exact thing you need to do to prevent clicks & pops. Suspecting the problem might be on the playback side of his particular setup, I asked him to record the sound on his computer the next time he tested and then kind of forgot about it for a bit.
Fast-forward a couple of days. Neither of us had followed up on the little clicky noise thing. While doing some video captures with OBS, I noticed that the sound was kind of terrible in some places, the explosions in particular. Maybe that was related?
While building a new version of my game, Compiling resources... showed up in my console and it suddenly dawned on me: What if my home-brew resource compiler somehow broke the audio files? I use it to encode all the .wav originals into Ogg Vorbis for deployment. Maybe a badly configured encoding setup caused the weird audio in OBS and for my brother? So I looked at the corresponding .ogg files, and to my surprise, it indeed had a small abrupt cut-off at the end. How could that happen? Only when I put both the original and the processed file next to each other, did I see what was actually going on:
It’s only half the file! How did that happen? And what made this specific file so special for it to happen? This is one of many files that I also convert from stereo to mono in preprocessing. So I hypothesized that might be the problem. No way I missed all of those files being cut in half though, or did I? So I checked the other files that were converted from stereo to mono. Apparently, I did miss it. They were all cut in half. So I took a look at the code. It looked something like this:
while (keep_encoding)
{
auto samples_in_block = std::min(BLOCK_SIZE, input.sample_count() - sample_offset);
if (samples_in_block != 0)
{
auto samples_per_channel = samples_in_block / channel_count;
auto channel_buffer = vorbis_analysis_buffer(&dsp_state, BLOCK_SIZE);
auto input_samples = input.samples() + sample_offset;
if (convert_to_mono)
{
for (int sample = 0; sample < samples_in_block; sample += 2)
{
int sample_in_channel = sample / channel_count;
channel_buffer[0][sample_in_channel] = (input_samples[sample] + input_samples[sample + 1]) / (2.f * 32768.f);
}
}
else
{
for (int sample = 0; sample < samples_in_block; ++sample)
{
int channel = sample % channel_count;
int sample_in_channel = sample / channel_count;
channel_buffer[channel][sample_in_channel] = input_samples[sample] / 32768.f;
}
}
vorbis_analysis_wrote(&dsp_state, samples_per_channel);
sample_offset += samples_in_block;
}
else
{
vorbis_analysis_wrote(&dsp_state, 0);
}
/* more stuff to encode the block using the ogg/vorbis API... */
}
Not my best work, as far as clarity and deep nesting goes. After staring at it for a while, I couldn’t really figure out what was wrong with it. So I built a small test program to debug into, and only then did I see what was wrong.
It was terminating the loop after half the file, which now seems pretty obvious given the outcome. But why? Turns out it wasn’t the convert_to_mono at all, but the whole loop. What’s really the problem here is mismatched and imprecise terminology.
What is a sample? The audio signal is usually sampled several thousand times (44.1kHz, 48kHz or 96kHz are common) per second to record the audio waves. One data point is called a sample. But that is only enough of a definition if the sound has a single channel. But all those with convert_to_mono==true were stereo, and that’s exactly were the confusion is in this code. One part of the code thinks in single-channel samples, i.e. a single sampling time-point has two samples in a stereo file, while the other part things in multi-channel samples, i.e. a single sampling time-point has only one stereo sample, that consists of multiple numbers. Specifically this line:
auto samples_in_block = std::min(BLOCK_SIZE, input.sample_count() - sample_offset);
samples_in_block and sample_offset use the former definition, while input.sample_count() uses the latter. The fix was simple: replace input.sample_count() with input.sample_count() * channel_count.
But that meant all my stereo sounds, even the longer music files, were missing the latter half. And this was not a new bug. The code was in there since the very beginning of the git history. I just didn’t hear its effects. For the sound files, many of them have a pretty long fade out in the second half, so I can kind of get why it was not obvious. But the music was pretty surprising. My game music loops, and apparently, it also loops if you cut it in half. I did not notice.
So what did I learn from this? Many of my assumptions while hunting down this bug were wrong:
My brother’s setup did not have anything to do with it.
Just because the original source file looked fine, I thought the file I was playing back was good as well.
The bad audio in OBS did not have anything to do with this, it was just recorded too loud.
The ogg/vorbis encoding was not badly configured.
The convert_to_mono switch or the special averaging code did not cause the problem.
I thought I would have noticed that almost all my sounds were broken for almost two years. But I did not.
What really cause the problem was an old programming nemesis, famously one of the two hard things in computer science: Naming things. There you have it. Domain language is hard.
I think this is because this sudden signal drop equates to a ‘burst’ in the frequency domain, but that is just an educated guess. If you know, please do tell. ↩︎
CMake has an option, CMAKE_UNITY_BUILD, to automatically turn your builds into unity-builds, which is essentially combining multiple source files into one. This is supposed to make your builds more efficient. You can just enable enable it while executing the configuration step of your CMake builds, so it is really easy to test. It might just work without any problems. Here are some examples with actual numbers of what that does with build times.
Project A
Let us first start with a relatively small project. It is a real project we have been developing, that reads sensor data, transports it over the network and displays it using SDL and Dear ImGui. I’m compiling it with Visual Studio (v17.13.6) in CMake folder mode, using build insights to track the actual time used. For each configuration, I’m doing a clean rebuild 3 times. The steps are the number of build statements that ninja runs.
Unity Build
#Steps
Time 1
Time 2
Time 3
OFF
40
13.3s
13.4s
13.6s
ON
28
10.9s
10.7s
9.7s
That’s a nice, but not massive, speedup of 124,3% for the median times.
Project A*
Project A has a relatively high number of non-compile steps: 1 step is code generation, 6 steps are static library linking, and 7 steps are executable linking. That’s a total of 14 non-compile steps, which are not directly affected by switching to unity builds. 5 of the executables in Project A are non-essential, basically little test programs. So in an effort to decrease the relative number of non-compile steps, I disabled those for the next test. Each of those also came with an additional source file, so the total number of steps decreased by 10. This really only decreased the relative amount of non-compile steps from 35% to 30%, but the numbers changes quite a bit:
Unity Build
#Steps
Time 1
Time 2
Time 3
OFF
30
9.9s
10.0s
9.7s
ON
18
9.0s
8.8s
9.1s
Now the speedup for the median times was only 110%.
Project B
Project B is another real project, but much bigger than Project A, and much slower to compile. It’s a hardware orchestration system with a web interface. As the project size increases, the chance for something breaking when enabling unity builds also increases. In no particular order:
Include guards really have to be there, even if that particular header was not previously included multiple times
Object files will get a lot bigger, requiring /bigobj to be enabled
Globally scoped symbols will name-clash across files. This is especially true for static globals or things in unnamed namespaces, which basically don’t do their job anymore. More subtly, things moved into the global namespace will also clash, such as the classes with the same name moved into the global namespace via using namespace.
In general, that last point will require the most work to resolve. If all fails, you can disable unity build on a target via set_target_properties(the_target PROPERTIES UNITY_BUILD OFF) or even just skip specific files for unity build inclusion via SKIP_UNITY_BUILD_INCLUSION. In Project B, I only had to do this for files generated by CMakeRC. Here are the results:
Unity Build
#Steps
Time 1
Time 2
Time 3
OFF
416
279.4s
279.3s
284,0s
ON
118
73.2s
76.6s
74.5s
That’s a massive speedup of 375%, just for enabling a build-time switch.
When to use this
Once your project has a certain size, I’d say definitely use this on your CI pipeline, especially if you’re not doing incremental builds. It’s not just time, but also energy saved. And faster feedback cycles are always great. Enabling it on developer machines is another matter: it can be quite confusing when the files you’re editing do not correspond to what the build system is building. Also, developers usually do more incremental builds where the advantages are not as high. I’ve also used hybrid approaches where I enable unity builds only for code that doesn’t change that often, and I’m quite satisfied with that. Definitely add an option to turn that off for debugging though. Have you had similar experiences with unity builds? Do tell!
The excellent {fmt} largely served as the blueprint for the C++20 standard formatting library. That alone speaks for its quality. But I was curious: should you now just use std::format for everything, or is fmt::format still a good option? In this particular instance, I wanted to know which one is faster, so I wrote a small benchmark. Of course, the outcome very much depends on the standard library you are using. In my case, I’m using Visual Studio 17.13.0 and its standard library, and {fmt} version 11.1.3.
I started with a benchmark helper function:
template <std::invocable<> F> steady_clock::duration benchmark(std::string_view label, F f)
{
auto start = steady_clock::now();
f();
auto end = steady_clock::now();
auto time = end - start;
auto us = duration_cast<nanoseconds>(time).count() / 1000.0;
std::cout << std::format("{0} took {1:.3f}us", label, us) << std::endl;
return time;
}
Then I called it with a lambda like this, with NUMBER_OF_ITERATIONS set to 500000:
int integer = 567800;
float real = 1234.0089f;
for (std::size_t i = 0; i < NUMBER_OF_ITERATIONS; ++i)
auto _ = fmt::format("an int: {}, and a float: {}", integer, real);
… and the same thing with std::format.
Interestingly, fmt::format only needed about 75%-80% of time of std::format in a release build, while the situation reversed for a debug build to about 106%-108%.
It seems hard to construct a benchmark with low overhead of other things, while still avoiding that the compiler can optimize everything away. My code assumes the compiler keeps the formatting even after throwing it away. So take all my results with a grain of salt!
Sometimes I need to get services from the DI just to create them. They would then register themselves with an event bus or some other system. I would not really call into them actively, and therefore I did not need access to the instances created. This could previously be done via something like (void)provider.get<my_autonomous_system>(), after all the services were registered. That works, but doesn’t scale up very well once you have a few of those. It would be much better to have something like provider.instantiate_all_autonomous_systems().
Some groups of systems I would instantiate and keep around just to call them in a totally homogeneous way, like system_one.update(), system_two.update(), etc.. Again it would be better to not require the concrete types at the call site and instead just get the requested systems and call their update() in a loop.
Query Interface
It turns out that both requirements can be solved by requesting instances for “a group” of registered services. In the case of the first requirement, that’s actually all that is needed, but for the second requirement, the instances also need to be processed in some way, e.g. upcasting or other forms of type-erasure. Here’s how I wanted it to look:
di di;
di.insert_unique<actual_update_thing_one>().trait<update_trait>();
di.insert_unique<actual_update_thing_two>().trait<update_trait>();
auto updaters = di.query_trait<update_trait>();
for (auto const& each : updaters)
each->update();
After registration with the DI, types can be marked with one or many traits, which can later be queried. For this example, the trait looks like this:
struct update_trait
{
using type = update_service*;
static update_service* type_erase(update_service* x)
{
return x;
}
};
It really just does an upcast to update_service, which is derived-from by both of the types. But it would be equally possible to use std::function<> in case the types are only compatible via duck-typing:
Of course, that changes the final loop in the example to:
for (auto const& each : updaters)
each();
So a traits type needs to contain a type-alias for the target type and a function to process the instance pointer into that target type, be it by wrapping it in some sort of adaptor or via upcasting. They type is separate, and not the return type of the function, because it has to be independent of the instance type that goes in, while the function can be a template and thus have different return (which is fine if they all convert to the target type).
Implementation
When you add a trait for a type T via the .trait<Trait>() template, I register a what I call a ‘resolver’, which is just a std::function<typename Trait::type()> that invokes Trait::type_erase(get_ptr<T>()). These are all put into a std::vector<>:
template <typename Trait> using trait_resolvers =
std::vector<std::function<typename Trait::type()>>;
For all the traits, these are stored in an std::unordered_map<std::type_index, std::any> where the key is typeid(Trait).
On query_trait<Trait>, I look into that map, get the trait_resolvers<Trait> out of it, and call each resolver to fill a new std::vector<typename Trait::type>, which is then returned and can be iterated by the user.
This implementation maps better to to the second use-case, but the first can be done with bogus type_erase function in the trait like this:
struct auto_create_trait
{
using type = int;
template <class T>
static int type_erase(T* x)
{
return 0;
}
};
This creates an std::vector<int> that isn’t needed, which is not ideal but not a deal-breaker either. On the other hand, it is not too hard to properly support void as the type with just two if constexpr (std::is_same_v<typename Traits::type, void>), one in the resolver lambda that omits the type_erase call and one in query_trait that omits storing the resolver result. This way, I can also use [[nodiscard]] on query_trait, and the trait can be written as just struct auto_create_trait { using type = void; };.
I often use std::string_view via the sv suffix for string constants in my code. If I need to associate something with those constants at runtime, I put it in an std::unordered_map with the constants as the keys.
Just a few days ago, I was using and std::unordered_map<std::string, ...> and wanted to .find(...) something in it with such a string constant. But that didn’t compile. From long ago, I remember that the type must be identical, and since there is no implicit conversion from std::string_view to std::string, I made that explicit to get it to compile. But wait. Didn’t C++ add support for using a different type than the key_type for the lookup? Indeed it did, in P0919R3 and P1690R1 from last decade. All major compilers seem to support it too. Then why wasn’t this working? It turns out that it’s not enabled by default, you need to explicitly enable it by supplying a special hasher. Here’s how I do it:
This is almost the same code as the sample given in the first of the two proposals. The using is_transparent = void; is how the feature is enabled and was changed in the second proposal.
I used to be pretty strictly against using either C++ using-directives or -declarations from within header files. It kind of stuck with me as a no-go. But that has changed in recent years.
There are now good cases where using can go into a header. For example, I do not really like putting things like…
using namespace std::string_literals;
using namespace std::string_view_literals;
using namespace std::chrono_literals;
…at the beginning of each source file. Did you know that you can pull all those (and some more) in with a single using namespace std::literals? Either way, in my newer projects, these usually go into one of the more prominent headers. Same goes for other literal operators such as those from the SI library. And so do using declarations for common vocabulary types. E.g. 2D or 3D vector types , in math heavy projects. Of course, they always go after the specific #include(s) the using is referencing. The benefits of doing that usually outweigh the danger of name-clashes and weird order dependencies.
There are cases where I still avoid using in headers however, and that is when the given header is ‘public’, i.e. being consumed by something that is not under my organization’s control. In that case, you better leave that decision to the library consumer.
Given a floating-point number x, it is quite easy to square it: x = x * x;, or x *= x;. Similarly, to find its cube, you can use x = x * x * x;.
However, when raising it to the 4’th power, things get more interesting: There’s the naive way: x = x * x * x * x;. And the slightly obscure way x *= x; x *= x; which saves a multiplication.
When raining to the 8’th power, the naive way really loses its appeal: x = x * x * x * x * x * x * x * x; versus x *= x; x *= x; x *= x;, that’s 7 multiplications version just 3. This process can easily be extended for raising a number to any power-of-two N, and will only use O(log(n)) multiplications.
The algorithm can also easily be extended to work with any integer power. This works by decomposing the number into product of power-of-twos. Luckily, that’s exactly what the binary representation so readily available on any computer is. For example, let us try x to the power of 20. That’s 16+4, i.e. 10100 in binary.
x *= x; // x is the original x^2 after this
x *= x; // x is the original x^4 after this
result = x;
x *= x; // x is the original x^8 after this
x *= x; // x is the original x^16 after this
result *= x;
Now let us throw this into some C++ code, with the power being a constant. That way, the optimizer can take out all the loops and generate just the optimal sequence of multiplications when the power is known at compile time.
template <unsigned int y> float nth_power(float x)
{
auto p = y;
auto result = ((p & 1) != 0) ? x : 1.f;
while(p > 0)
{
x *= x;
p = p >> 1;
if ((p & 1) != 0)
result *= x;
}
return result;
}
Interestingly, the big compilers do a very different job optimizing this. GCC optimizes out the loops with -O2 exactly up to nth_power<15>, but continues to do so with -O3 on higher powers. clang reliably takes out the loops even with just -O2. MSVC doesn’t seem to eliminate the loops at all, nor does it remove the multiplication with 1.f if the lowest bit is not set. Let me know if you find an implementation that MSVC can optimize! All tested on the compiler explorer godbolt.org.