
In my years of managing software development projects, I’ve come to apply a simple metric to each project to determine its “personality”. The metric consists of only two aspects (or dimensions): success and noise. Each project strives to be successful in its own terms and each project produces a certain amount of “noise” while doing so. Noise, in my definition, is necessary communication above the minimum. A perfectly silent project isn’t really silent, there are just no communicated problems. That doesn’t mean there aren’t any problems! A project team can silently overcome numerous problems on their own and still be successful. The same team can cry for help at each and any hurdle and still fail in the long run. That would mean a lot of noise without effect. I call such a project a “Burning Ox”.
Success vs. Noise
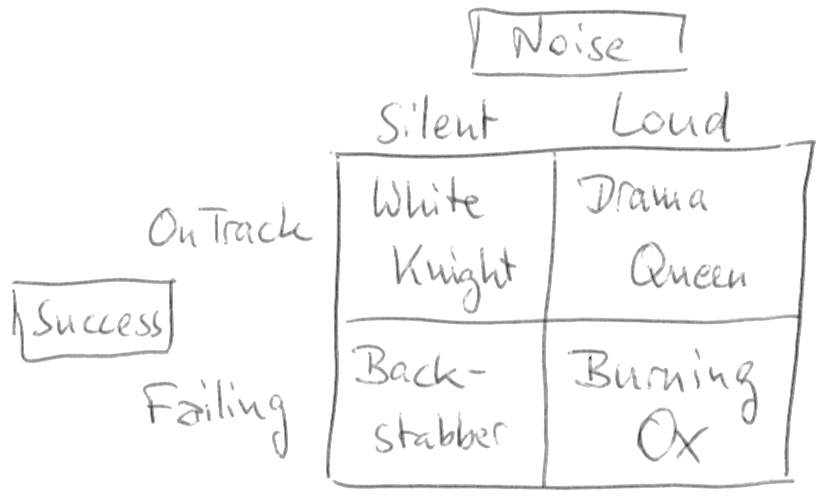
As you can see, there are four types of projects with this metric. The desired type of project is the “White Knight” in the top-left quarter, while the “Burning Ox” in the bottom-right is the exact opposite. Let’s review all four types:
- White Knight (silently on track): A project that is on track, tackles every upcoming challenge on its own, reports its status but omits the details and turns out to be a success is the dream of every project manager. You can let the team find its own way, document their progression and work on the long-term goals for the team and the product. It’s like sailing in quiet waters on a sunny day. Nothing to worry about and a pleasant experience all around.
- Drama Queen (loud, but on track): This project is ultimately headed towards success, but every obstacle along the way results in emergency meetings, telephone conferences or e-mail exchanges. The number of challenges alone indicate that the team isn’t up to the task. You are tempted to micro-manage the project, to intervene to solve the problems and ensure success or at least progress. But you are bound to recognize some or even most problems as non-existent. The key sentence to say or think is: “Strange, nobody else ever had this problem and we’ve done it a dozen times before”. If you are a manager for several projects, the Drama Queens in your portfolio will require the majority of your time and attention. You’ll be glad when the project is over and “peaceful” times lie ahead.
- Backstabber (silent and a failure): This is the biggest fear of every manager. The project seems alright, the team doesn’t report any problems and everything looks good. But when the cards need to be put on the table, you end up with a weak combination. It’s too late to do anything about the situation, the project is a failure. And it failed because you as the manager didn’t dig deeper, because you let them fool you. No! If you look closer, it failed because nobody dug deeper and everybody was in denial. You’ll see the warning signs in retrospective. You will become more paranoid in your next project. You’ll lose faith in the project status reports of your teams. You’ll inquire more and micro-manage the communication. You’ll become a skittish manager because of this unpleasant experience. Backstabber projects have horrendous costs for the social structure of a company.
- Burning Ox (loud and failing): The name stems from an ancient war tactics when the enemy’s camp was overrun by a horde of oxen with burning torches bound to the horns. The panicked animals wreaked havoc along their way and started fires left and right. A Burning Ox is helpless in the situation, but takes it out on anybody and anything near it, too. This project is bound to fail, the team is in it way over their heads and no amount of support from your side or help from the outside can safe it. Well, experienced firefighters might work wonders, but they are expensive and rare (we know because we are often called in for this job). If you find a Burning Ox in your project portfolio (and you will know it, because a Burning Ox screams on the top of his lungs), prepare yourself for the inevitable: The project will fail, in scope (missing functionality), budget (higher costs) and/or time (delayed delivery). You better start with damage control now or make a call to a firefighter you can trust.
Easy assessment
This project management metric is not meant for deep inspection, but for easy assessment and quick communication. You can convey your desired communication style and the fact that everybody involved with the project is partly responsible for its success or failure. The metric states that too much detail is not helpful and too little detail can be disastrous. It also shows that loudly failing projects are not the fault of the project team alone (the ox cannot help being used as a living torch), but that the prerequisites of the project weren’t met.
Takeaway
If you are not a project manager, what can you learn from this blog post? Ask yourself if you require too much help from your manager, forcing him/her to switch into the micro-management gear, even if you could solve the problem yourself. If you cannot, ask yourself if you think that you can deliver the project in scope, time and budget or if you already smell the fire. If you can smell the fire, is your manager aware? Are you telling him/her in unclouded words about your perceived state of the project? Did you attempt to communicate your perception/feeling at least twice? If not, your manager might be shocked that he/she took care of a Backstabber project. A failing project is not your fault! You would only be to blame for the continued hiding of a known fact.
If you are a project manager, take a piece of paper, draw the metric’s chart and try to pin-point the position of all your projects. Be as honest and exact as possible. Is it really a Burning Ox or “just” a Drama Queen? Are your White Knights really above reproach or is their loyality questionable? What questions could you ask to try to unveil hidden problems, even those that nobody is aware of yet?
These quick, repeated assessments help me to manage my schedule and not forget about the silent projects because the loud projects always ellbow their way into my attention.






 https://commons.wikimedia.org/wiki/User:Kneiphof")
