
Using an object-relational-mapper (ORM) to persist your entities, manage their state and query subsets for lists or reports is a wide-spread practice and may speed up your development.
If not used correctly, it may introduce unexpected performance problems because of unefficient default queries and the overhead this mapping introduces as most of the time table rows are converted to domain objects. Often this results in many queries and the n+1 query problem.
Nevertheless, the benefits of using an ORM may outweigh the problems and most problems can be mitigated by features and a correct usage of the tool.
Today I want to present a performance problem we had using GORM/Hibernate and how we easily fixed it without major code restructuring or workarounds.
The Problem
We used a HQL-query to load quite a lot of entities which took about 3 seconds. This was acceptable for our customer. If the user however tried to narrow down the results using a filter loading a smaller amount of the same entities took over 1 minute. Obviously, this was totally unacceptable and counter-intuitive.
The Analysis
Further analysis revealed, that a particular part of the WHERE-clause was responsible for the observed slowdown:
FROM Report r
WHERE r.project.proposal.id = p.id
So we did filter the root entity Report on an entity called Proposal but needed to load an associated Project entity for all reports to consider. So even if we are just using entity-ids to filter the innocently looking path r.project.proposal.id leads to loading and mapping of hundreds of Project entities.
The Solution
In our example we can fortunately do a lot better without big changes to our domain model, the application code or the query.
The relevant part of the schema looks like below:
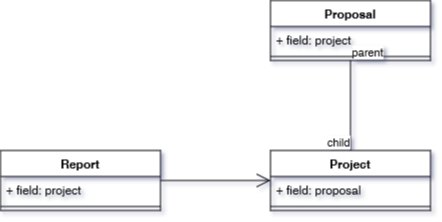
In the above schema we can see, that both, a Report and a Proposal are associated with a certain project. Remember, that in Hibernate your entities contain only the id of their one-to-one mapped sub-entities by default. This means that if we change the filter clause to
WHERE r.project.id = p.project.id
we skip loading and mapping of all the Project entities and only load the needed reports and proposals. Since they both contain the project id we can use that in our filter. This resulted in more than a 10x speedup with such a simple and non-invasive change.
General Takeaway
ORMs can be a great tool but it is very easy to shoot yourself into the foot. With enough care you can achieve both simple code and good performance but you may run into non-obvious problems every now and then.




