Recently, a friend recommended the talk “Love your bugs” by Allison Kaptur to me. It’s a good talk with a powerful message: Every bug is a chance to learn. The only prerequisite for this chance: You need to be aware of the bug. You need to see it and then understand and fix it.
What if you don’t see a bug for over a decade?
You can still learn from it – a lot. Here is a story about a bug that lingered in my code for twelve years and had impact on the software results without anybody, including me, noticing.
Let’s say the software is a measurement system that records physical measurement values that cannot be reenacted easily. The samples are measured in rapid succession and then stored away. The measurement results act as a quality quantifier as in “the sample was this good at that time”. The sample’s quality diminishes over time, even with perfect storage conditions. And just to be sure that the measurement is accurate, it isn’t performed once, but twice in quick succession: The measurement device traverses the sample in one direction, recording the values and uses the return path for a second measurement. This results in two measurement streaks that should, in theory, be very similar.
The raw measurement values are aggregated in different ways. In the final report, the maximum value over both measurement streaks is the most prominent and most important aspect. There is nothing exciting or error-prone about finding the maximum value in a value series, even twelve years ago. But I tested the code nonetheless. The whole value aggregation code was under test and had a good test coverage. All tests showed their thumbs up.
But twelve years ago, at the end of a workweek, on a Friday at 17 o’clock, I made a small and easy refactoring to the code. I know this in such detail because of the wonders of version control. Without version control, I probably would have learnt a lot less from this bug.
The code before the refactoring contained two nearly identical sections for the measurement streaks, making it duplicated code. There were only two differences: The first section of code counted from 0 to 99 and stored the values in the first streak’s array. The second section counted from 99 to 0, because the measurement device travels backwards over the sample, and stored the values into the second array.
My refactoring brought both pieces of code together: A new method with two parameters was introduced and called at both places. The first parameter specified a series of positions (0 to 99 or backwards), the second parameter specified the array to store into. All automated tests approved the changes. My manual testing showed no differences. The refactoring was going live.
Twelve years later, while working on a new engine for the measurement device, the customer took the raw values from the journal and performed some manual calculations. The maximum value calculation was wrong. It wasn’t wrong all of the time, but also not correct for all measurements. When it went wrong, it selected the second greatest value or, seldom, the third greatest value as the maximum value.
All the tests still insisted that everything is correct – as it was for twelve long years. There was no other change to the code that could affect the aggregation in any way.
There are two different ways that lead me to find the bug’s origin. The first way was to inspect the trail of commits in the area of code that performs the aggregation. My findings were that the abovementioned refactoring was the most likely culprit. The second way was to write more tests to ensure that yes, the maximum value calculation was indeed correct if given the correct values. Using the examples my customer had examined, I could prove with enough certainty that, given the input of all 200 values, the correct maximum value was returned in all cases. The aggregation therefore wasn’t given all values!
And that lead directly to the bug: The first measurement streak used the same array to store the values as the second streak. During the refactoring, I must have copied and pasted the call to the new method and forgotten to change the second parameter. Of 200 measured values, only 100 got stored permanently. The first 100 values were stored and promptly overwritten as the measurement device returned to its park position. Change the calls to store in both arrays and everything works like intended and like before the refactoring.
How did no test, automated or manual, catch this bug? It turns out that most automated tests were too focussed to indicate a problem. All unit tests that secured the maximum value calculation used given sets of values, they didn’t care about the origin of these value sets. The integration tests that covered the whole measurement process should have raised objections to the refactoring. But they used given sets of measurement values, too. And by chance, the given maximum value was in the second measurement streak. In fact, the given set of measurement values was produced by a loop that just increased a value. The greatest value was always the last one.
The manual tests had the same problem: The simulated measurement device produced measurement values that were either fixed or random. If your whole measurement uses the same fixed values, you don’t see it if half of them went missing. And if your measurement uses random values, you’ll have to pay close attention to a detail that isn’t in focus because it is unchanged. Except that one time when it was changed recently. Remember the change date? Friday afternoon, only minutes before the weekend? Not the best time to manually test a change that is a simple standard refactoring, after all.
So, what have I learnt? First: automated tests, even with great test coverage, aren’t enough. There is so much leeway in the setup of these tests that they will have blind spots without your knowledge. Second: A code review by another human (or even by the same human, some days later) might have caught the bug. It was painfully obvious in hindsight. The problem? “Might have” is an heuristics, just like your automated tests are.
My guess is that mutation testing would have shown the blind spot of the existing tests – among several hundred others. The heuristics is now your trained eye that sifts through the results and separates false positives from true positives.
Right now, I’ve fixed the bug, kept all additional tests and added one more: An integration test that performs a measurement with fixed values and checks nothing else but if all 200 values are stored at the end of the measurement. It’s oddly specific, but conveys this story in an automated fashion.
Oh, and I made another refactoring: I’ve replaced the arrays with collections. Hopefully, I won’t regret this one twelve years in the future. I’ve made it on a Monday.


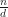
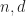 for floating point computation can be quite appealing. However, if you really try this in practice, you are likely to end up with unacceptable performance (for an example, see the post
for floating point computation can be quite appealing. However, if you really try this in practice, you are likely to end up with unacceptable performance (for an example, see the post 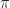 and
and  are not rational.
are not rational.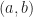 of rational numbers
of rational numbers  . The idea is, that
. The idea is, that 
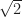 that we added to the rationals is the solution of the polynomial equation
that we added to the rationals is the solution of the polynomial equation or equivalently
or equivalently 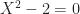
 or
or 
 are rational numbers).
are rational numbers). is as small as possible. Then the new numbers can be represented as tuples of length
is as small as possible. Then the new numbers can be represented as tuples of length  as the polynomial
as the polynomial
 . You can check out how this recipie does the right thing in the example with
. You can check out how this recipie does the right thing in the example with 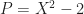 . To avoid confusion, let us put the polynomial defining in which extension of the rationals we are into the number. So know, a number is a tuple
. To avoid confusion, let us put the polynomial defining in which extension of the rationals we are into the number. So know, a number is a tuple .
. we will get two extensions. So we have
we will get two extensions. So we have 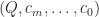 we don’t know how to perform basic arithmetic unless
we don’t know how to perform basic arithmetic unless 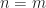 and
and  .
.
 .
.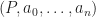
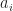 are from some fixed extension and
are from some fixed extension and  with lesser degree (and coefficients in the extension) such that their product
with lesser degree (and coefficients in the extension) such that their product 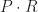 is equal to
is equal to 
