Java’s java.sql package provides a general API for accessing data stored in relational databases. It is part of JDBC (Java Database Connectivity). The API is relatively low-level, and is often used via higher-level abstractions based on JDBC, such as query builders like jOOQ, or object–relational mappers (ORMs) like Hibernate.
If you choose to use JDBC directly you have to be aware that the API relatively old. It was added as part of JDK 1.1 and predates later additions to the language such as generics and optionals. There are also some pitfalls to be avoided. One of these pitfalls is ResultSet’s wasNull method.
The wasNull method
The wasNull method reports whether the database value of the last ‘get’ call for a nullable table column was NULL or not:
int height = resultSet.getInt("height");
if (resultSet.wasNull()) {
height = defaultHeight;
}
The wasNull check is necessary, because the return type of getInt is the primitive data type int, not the nullable Integer. This way you can find out whether the actual database value is 0 or NULL.
The problem with this API design is that the ResultSet type is very stateful. Its state does not only change with each row (by calling next method), but also with each ‘get’ method call.
If any other ‘get’ method call is inserted between the original ‘get’ method call and its wasNull check the code will be wrong. Here’s an example. The original code is:
var width = rs.getInt("width");
var height = rs.getInt("height");
var size = new Size(width, rs.wasNull() ? defaultHeight : height);
A developer now wants to add a third dimension to the size:
var width = rs.getInt("width");
var height = rs.getInt("height");
var depth = rs.getInt("depth");
var size = new Size(width, rs.wasNull() ? defaultHeight : height, depth);
It’s easy to overlook the wasNull call, or to wrongly assume that adding another ‘get’ method call is a safe code change. But the wasNull check now refers to “depth” instead of “height”, which breaks the original intention.
Advice
So my advice is to wrap the ‘get’ calls for nullable database values in their own methods that return an Optional:
Optional<Integer> getOptionalInt(ResultSet rs, String columnName) {
final int value = rs.getInt(columnName);
if (rs.wasNull()) {
return Optional.empty();
}
return Optional.of(value);
}
Now the default value fallback can be safely applied with the orElse method:
var width = rs.getInt("width");
var height = getOptionalInt(rs, "height").orElse(defaultHeight);
var depth = rs.getInt("depth");
var size = new Size(width, height, depth);
Containers are a great way of running your software in an environment that you defined and no one else needs to maintain of even know about. This is especially true if your software provides its service using a network port. All that operators have to provide is the execution platform for the container and the required resources.
Tango servers fit quite well into this type of software: Essentially they provide a service over the network. Unfortunately, they need a tango control system to be fully usable, so thats some other services. Luckily, there are docker images for this so building a stack of containers to run your Tango server in the scope of a control system is quite easy (sample docker-compose.yml):
Example Dockerfile for the image my-ts used for the my-tango-server container:
FROM debian:buster
WORKDIR /tango-server
COPY ./my-tango-server .
RUN DEBIAN_FRONTEND=noninteractive apt-get install -y ./*.deb
CMD my-tango-server myts
Unfortunately this naive approach has the following issues:
The network port of our tango server changes with each restart and is not available from outside the docker stack
The tango server communicates the internal IP-Address of its container to the tango database so connection attempts from the outside fail even if the port is correct
Even though the tango server container depends on the tango control system container the tango server might start up before the tango control system is available.
Let us tackle the issues one by one.
Expose a fixed port for the Tango server
This is probably the easiest issue to fix because it is well documented for OmniORB and widely used. So let us change docker-compose.yml to expose a port and pass it into the container as an environment variable:
FROM debian:buster
WORKDIR /tango-server
COPY ./my-tango-server .
RUN DEBIAN_FRONTEND=noninteractive apt-get install -y ./*.deb
CMD my-tango-server myts -ORBendPoint giop:tcp::$TANGO_SERVER_PORT
Fine, now our Tango server always listens on a defined port and that same port is exposed to the outside of our docker stack.
Publish the correct IP/hostname of the Tango server
I found it hard to find documentation about this and how to put it on the command line correctly but here is the solution to the problem. The crucial command line parameter is -ORBendPointPublish . We need to pass a hostname of the host machine into the container and let OmniORB publish that name (tango-server.local in our example):
FROM debian:buster
WORKDIR /tango-server
COPY ./my-tango-server .
RUN DEBIAN_FRONTEND=noninteractive apt-get install -y ./*.deb
CMD my-tango-server myts -ORBendPoint giop:tcp::$TANGO_SERVER_PORT -ORBendPointPublish giop:tcp:$TANGO_SERVER_PUBLISH
Waiting for availability of a service
This one is not specific to our tango server and the whole stack but a general problem when building stacks where one service depends on another one being up and listening on a network port. Docker compose takes care of the startup order of the containers but does not check for the readiness of services running in the containers. In linux containers this can easily be achieved by using the small shell utility wait-for-it. Here we only need to make some changes to our Dockerfile:
Depending on your distribution/base image installation of the tool (or other similar alternatives like dockerize or docker-compose-wait).
Summing it up
After moving some rocks out of the way it is dead easy to deploy your tango servers together with a complete tango control system to any host platform providing a container runtime. You do not need to delivery everything in one single stack if you do not want to. Most of the stuff described above works the same when deploying tango control system and tango servers in independent stacks or as separate containers even on multiple hosts.
When I’m tasked with commenting on a software architecture, my first step is to request or draw a map of all distinguishable elements of the software system and give them relationships to each other. This inevitably results in a boxes-and-arrows type of diagram that serves as a base for all future communication about the subject. Having a shared representation about a system is a great way to pinpoint discussions and focus on a particular area without forgetting the rest completely.
When I’m tasked with commenting on IT infrastructure, my first step is to request or draw a map of all distinguishable elements of the IT architecture (or “IT landscape”, a term that I actually prefer because it conveys better that a lot of things on this scale happen unplanned) and give them relationships to each other. Once again, we are drawing boxes and connecting them with arrows.
Being able to rely on this map is an essential base for all communication about IT architecture. And if you know how to read the map, it directs your efforts of consolidating your IT architecture nearly intuitively.
In this blog entry, we talk about drawing the map. The second part goes into interpretation of the map, the third part emphasizes actionable steps based on the map and our interpretation of it. Based on questions and discussion, there might even be a fourth part, but that’s not planned yet.
Your initial boxes
Beginning the IT architecture map is easy: Draw a box and give it a name. The name should correspond to an element of your work environment that is distinguishable from other elements. Note how I don’t say “system” or “service” or “server”. For an IT architecture, these words describe an implementation, a particular manifestation of the architecture. They don’t belong on the map (or this map). If you cannot see the difference yet, think about the floor plan of a house. It doesn’t tell you about the material the house is made of and you can use the same floor plan for a wooden cabin or a marble mansion (barring some pesky statics limitations that I don’t have a clue of). In our IT architecture map, each box represents a “thing” that will at the latest get a name the minute it stops working.
There will be boxes in your IT architecture map that don’t relate to anything else. That’s fine and not a problem, as long as the box relates to humans. If you cannot find a meaningful relationship between the box and humans or other boxes, you’ve found a relict. This is in fact one of the hardest tasks in IT architecture analysis, so congratulations!
Adding relationships
Every other box interacts with its environment in some manner. Again, the concrete implementation of that interaction is not important for our map. For our current view on the landscape, it makes no difference if a software system uses HTTP calls to a server or a computer tranfers bytes over RS232 wire to an appliance box. The fact that one box relies on the availability of another box is all that matters. That’s the essence of our arrows: Box 1 requires box 2 to be “online” in order to perform its duties. Without box 2, the functionality offered by box 1 will be limited, down to a point where it is no longer useful to others. Our arrows denote dependencies between boxes. If you happen to be a software developer: we don’t talk about code dependencies here. Also, even if closely related, we don’t mean format or protocol dependencies. We just state that if box 2 “goes down”, box 1 will follow closely.
This is the base for a rule of thumb about dependency arrows: Don’t draw them bidirectionally. Each arrow has one clear direction (like box 1 –> box 2). If you find that box 2 also depends on box 1, you should draw two arrows in opposite directions. As a preview for the interpretation step: This dependency cycle is a sore spot in your current architecture. It means that your two boxes appear as one to the outside. It means that you cannot replace one part without the other. The replaceability of single boxes is an important aspect of your landscape’s health.
Making it readable
When you’ve placed your boxes and drawn the arrows, it’s time to improve on the map’s layout. A guideline for the layout is that arrows shouldn’t intersect each other. Another guideline is that boxes that are semantically related should be near each other on the map. These two requirements alone often result in a lot of movement and experiments. You might want to use a software that allows for these experiments without much effort.
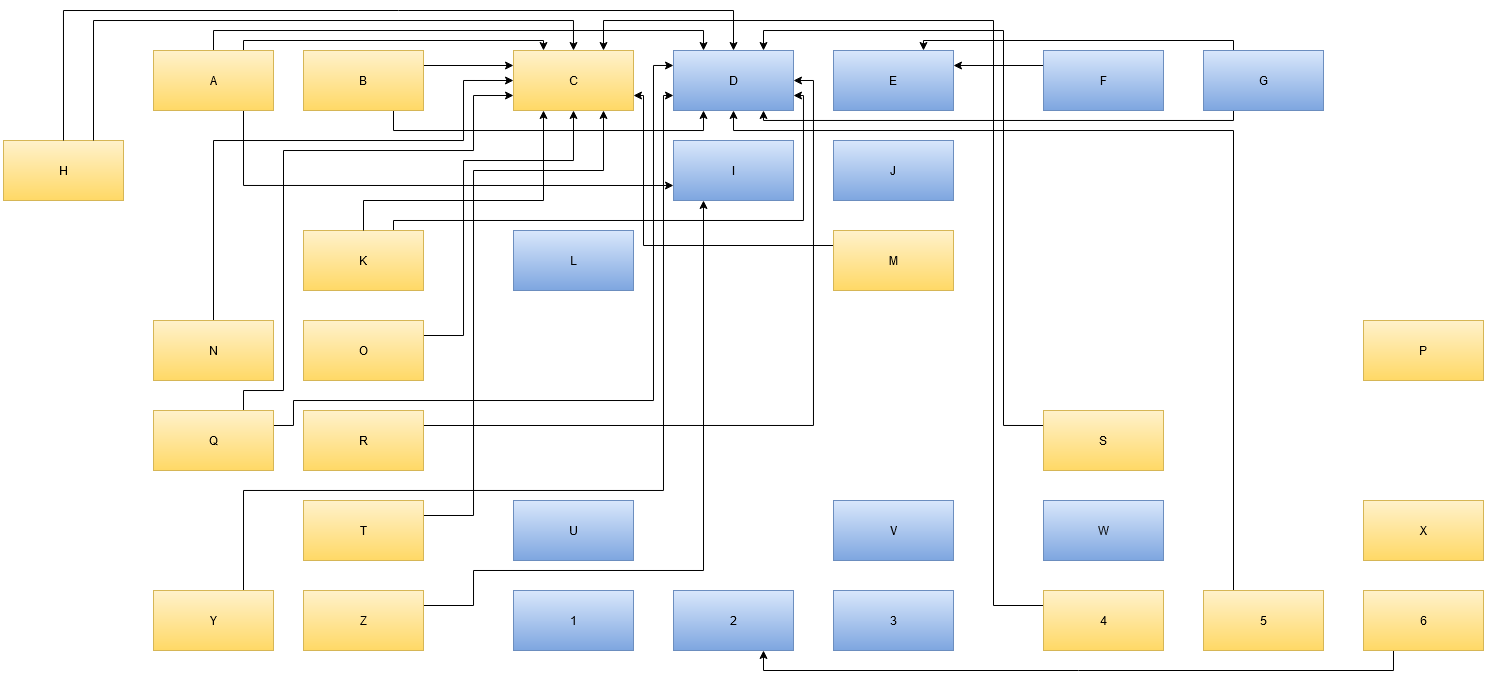
You’ll recognize a fitting layout when you see it. The map corresponds to your internal landscape representation enough to be useful in discussions. It might look like this real example:
First thing you’ll notice it that the names are replaced by denotations with zero meaning. In a real map, the box “C” might be named “time tracking” and box “D” could be labelled “issue tracking”. The name should indicate the responsibility of the element/box. You can also add the current implementation of that responsibility, if that makes things clearer. In our example, box “D”, indicating “issue tracking” might have “(JIRA)” added to the description. Just be aware that your organization probably needs another issue tracking system in that place even if JIRA falls out of favour. Following your arrows backwards, you’ll know which other elements of your landscape will be affected by this replacement. More on that in the next part about interpreting the map.
Evolving the map
Another thing you probably scoffed at is the intersecting arrows in the example. The map’s author came up with this layout as the best representation when the map had fewer boxes. With each subsequently added box, another arrow or two tried to reach the “center”. The intersections are a direct consequence of the emergence of a “center”. This is an important finding of your map: Being able to identify your map’s center and deduce meaning from it. To spoiler a bit: If your center is “time tracking” and “issue tracking”, you probably charge money per hour to solve other people’s problems.
Conclusion
You’ve probably seen how drawing an IT landscape map can benefit your organization and your discussions about its present and future. One thing you should keep in mind is that the map should reflect the current state and not your desired state of your organization’s IT architecture. That’s what will be addressed in part 3 of this series. Stay tuned!
Over the turn of the year I took some weeks off, in order to work out some private projects, finish some books that I had halfway-finished for far too long, and of course, to reflect about what such concepts like New Year actually could mean. As usual, the short answer is… not much per se, but one can seize the occasion to contrive a few goals for the year. You know, not these mundane, marginal resolutions like “on February 20th I will definitely go for a run”, or ambiguous abstracts like “in 2021 I‘m finally gonna be a people person!”, but a more profound search for something new, a kind of evaluation of undiscovered instrument in the toolkit of one‘s being, the juicy stuff.
Now we‘ve seen for quite some years, that the world of self-improvement likes to border on the superstitious. From particularly fine-tuned compositions of one‘s diet plan, to the sheer religious belief in certain routines, there‘s no shortage in shady suggestions that draw their data from unique success stories that makes me wonder: Even if there was a kind of biological truth to these underlying claims, how could I survive the cringing of my heart that I would experience by reading these articles?
A special downside of solutions of the kind „collection of very intricate details“ is that they aim to intervene in your life at a very incessant level. Which is, you have to think about them all day in fear of breaking the patterns, i.e. you not only distract yourself from the stuff you actually want to do, but also not giving you a certainty of feedback in either – if something appears to help – what exactly it is that helps, or – if there‘s no effect to be noticed – which detail is maybe done wrong in order to blast away all the other efforts. I guess I would only resort to such methods if I had the impression that something‘s seriously wrong with me, and I currently don‘t notice people telling me this more than once a week, so it‘s fine.
Then there are the kind of solutions that I consider just minor variations of the stuff that one already sort of knows. E.g. I don‘t consider “doing some physical movement once in a while is quite ok” as a real form of “bio-hack”, as that is just common knowledge. Ok, you still have to actually apply it, fair enough, but from an intellectual standpoint it’s boring.
So anyway, I‘m still convinced there ought to be some ways of modifying your life style at quite a beginner-suitable level, one that can easily be opted-in, low requirement of risk or investion, and that‘s where I usually start listening.
A few years back, for instance, for me that was the discovery of intermittent fasting, which in my case happened to show nearly instantaneous effects, mostly positive (e.g. for subjective impressions of my attention and overall well-being). This is something that I‘d at least easily recommend trying out a few times, but as for me, right now, I‘m not really inclined in implementing it right now.
One can probably be a bit ambivalent about all these over-the-(online-)counter supplement prescriptions that are listed everywhere. I‘m not going to recommend the regular use of any substance here, but there‘s plenty of articles about nootropics or other cognitive enhancers; some of these articles also border on the quasi-religious realm, others appear more scientific (the usage of coffee is living in the same domain, and I like that a lot) – so I‘ll leave it to the reader to form his own opinion.
Having said that, I can now finally reveal what this post is all about, as I seem to have found another intriguing way which I‘m just trying out now since a few weeks. I found the claim that it is advantageous of sleeping on an inclined bed. That certainly was outside my curretn scope, the underlying claims are about an improved flow of your glymphatic system, as well as pressure regulation. Be that as it may, it doesn‘t sound harmful and it‘s easily obtainable: by raising your bed‘s head end about 10-15cm with some suitable, stable risers, available for below 20€. I found only weird for the first night and seemed to wake up in a better mood. Together with such nice add-on as a wake up light (if you have one), this certainly qualifies as a “why didn’t anyone tell me earlier?”-moment for me.
So, if you have more intriguing bio-hacks that you consider definitely on the non-quacky side, I‘m interested 🙂