Deployment is a crucial step in every development project. Without shipping no one would ever see our work (and we get no feedback if our work is good).

Often we fear deploying to production because of the effort involved and the errors we make. Questions like ‘what if we forget a step?’ or ‘what if the new version we install is buggy?’ buzz in our mind.

Deployment needs to be a non-event, a habit. For this we need to automate every step besides the first one: clicking a button to start deployment.

On Linux we have wonderful tools for this but what if you are stuck with deploying to Windows?

Fear not, brave developer! Even on Windows we can use a package manager to install and rollback buggy versions. Let me introduce you to chocolatey.

Chocolatey (or choco in short) uses the common NuGet package format. Formerly developed for the .net platform we can use it for other platforms, too. In our following example we use a simple Java application which we install as a service and as a task.
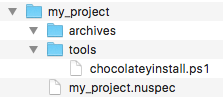
Setting up we need a directory structure for the package like this:

We need to create two files: one which specifies our package (my_project.nuspec) and one script which holds the deployment steps (chocolateyinstall.ps1). The specification file holds things like the package name, the package version (which can be overwritten when building the package), some pointers to project, source and license URLs. We can configure files and directories which will be copied to the package: in our example we use a directory containing our archives (aptly named archives) and a directory containing the installation steps (named tools). Here is a simple example:
<?xml version="1.0" encoding="utf-8"?>
<!-- Do not remove this test for UTF-8: if “Ω” doesn’t appear as greek uppercase omega letter enclosed in quotation marks, you should use an editor that supports UTF-8, not this one. -->
<package xmlns="http://schemas.microsoft.com/packaging/2015/06/nuspec.xsd">
<metadata>
<id>my_project</id>
<title>My Project (Install)</title>
<version>0.1</version>
<authors>Me</authors>
<owners>Me</owners>
<summary></summary>
<description>Just an example</description>
<projectUrl>http://localhost/my_project</projectUrl>
<packageSourceUrl>http://localhost/git</packageSourceUrl>
<tags>example</tags>
<copyright>My company</copyright>
<licenseUrl>http://localhost/license</licenseUrl>
<requireLicenseAcceptance>false</requireLicenseAcceptance>
<releaseNotes></releaseNotes>
</metadata>
<files>
<file src="tools\**" target="tools" />
<file src="archives\**" target="archives" />
</files>
</package>
This file tells choco how to build the packages and what to include. For the deployment process we need a script file written in Powershell.

A Powershell primer
Powershell is not as bad as you might think. Let’s take a look at some basic Powershell syntax.
Variables
Variables are started with a $ sign. As in many other languages ‘=’ is used for assignments.
$ErrorActionPreference = 'Stop'
Strings
Strings can be used with single (‘) and double quotes (“).
$serviceName = 'My Project'
$installDir = "c:\examples"
In double quoted strings we can interpolate by using a $ directly or with curly braces.
$packageDir = "$installDir\my_project"
$packageDir = "${installDir}\my_project"
For escaping double quotes inside a double quoting string we need back ticks (`)
"schtasks /end /f /tn `"${serviceName}`" "
Multiline strings are enclosed by @”
$cmdcontent = @"
cd /d ${packageDir}
java -jar ${packageName}.jar >> output.log 2>&1
"@
Method calls
Calling methods looks a mixture of command line calls with uppercase names.
Write-Host "Stopping and deleting current version of ${packageName}"
Get-Date -format yyyyddMMhhmm
Copy-Item $installFile $packageDir
Some helpful methods are:
- Write-Host or echo: for writing to the console
- Get-Date: getting the current time
- Split-Path: returning the specified part of a path
- Join-Path: concatenating a path with a specified part
- Start-Sleep: pause n seconds
- Start-ChocolateyProcessAsAdmin: starting an elevated command
- Get-Service: retrieving a Windows service
- Remove-Item: deleting a file or directory
- Test-Path: testing for existence of a path
- New-Item: creating a file or directory
- Copy-Item: copying a file or directory
- Set-Content: creating a file with the specified contents
- Out-Null: swallowing output
- Resolve-Path: display the path after resolving wildcards
The pipe (|) can be used to redirect output.
Conditions
Conditions can be evaluated with if:
if ($(Get-Service "$serviceName" -ErrorAction SilentlyContinue).Status -eq "Running") {
}
-eq is used for testing equality. -ne for difference.
Deploying with Powershell
For installing our package we need to create the target directories and copy our archives:
$packageName = 'myproject'
$installDir = "c:\examples"
$packageDir = "$installDir\my_project"
Write-Host "Making sure $installDir is in place"
if (!(Test-Path -path $installDir)) {New-Item $installDir -Type Directory | Out-Null}
Write-Host "Making sure $packageDir is in place"
if (!(Test-Path -path $packageDir)) {New-Item $packageDir -Type Directory | Out-Null}
Write-Host "Installing ${packageName} to ${packageDir}"
Copy-Item $installFile $packageDir
When reinstalling we first need to delete existing versions:
$installDir = "c:\examples"
$packageDir = "$installDir\my_project"
if (Test-Path -path $packageDir) {
Remove-Item -recurse $(Join-Path $packageDir "\*") -exclude *.conf, *-bak*, *-old*
}
Now we get to the meat creating a Windows service.
$installDir = "c:\examples"
$packageName = 'myproject'
$serviceName = 'My Project'
$packageDir = "$installDir\my_project"
$cmdFile = "$packageDir\$packageName.cmd"
if (!(Test-Path ($cmdFile)))
{
$cmdcontent = @"
cd /d ${packageDir}
java -jar ${packageName}.jar >> output.log 2>&1
"@
echo "Dropping a ${packageName}.cmd file"
Set-Content $cmdFile $cmdcontent -Encoding ASCII -Force
}
if (!(Get-Service "${serviceName}" -ErrorAction SilentlyContinue))
{
echo "No ${serviceName} Service detected"
echo "Installing ${serviceName} Service"
Start-ChocolateyProcessAsAdmin "install `"${serviceName}`" ${cmdFile}" nssm
}
Start-ChocolateyProcessAsAdmin "set `"${serviceName}`" Start SERVICE_DEMAND_START" nssm
First we need to create a command (.cmd) file which starts our java application. Installing a service calling this command file is done via a helper called nssm. We set it to starting manual because we want to start and stop it periodically with the help of a task.
For enabling a reinstall we first stop an existing service.
$installDir = "c:\examples"
$serviceName = 'My Project'
$packageDir = "$installDir\my_project"
if (Test-Path -path $packageDir) {
Write-Host $(Get-Service "$serviceName" -ErrorAction SilentlyContinue).Status
if ($(Get-Service "$serviceName" -ErrorAction SilentlyContinue).Status -eq "Running") {
Start-ChocolateyProcessAsAdmin "Stop-Service `"${serviceName}`""
Start-Sleep 2
}
}
Next we install a task with help of the build in schtasks command.
$serviceName = 'My Project'
$installDir = "c:\examples"
$packageDir = "$installDir\my_project"
$cmdFile = "$packageDir\$packageName.cmd"
echo "Installing ${serviceName} Task"
Start-ChocolateyProcessAsAdmin "schtasks /create /f /ru system /sc hourly /st 00:30 /tn `"${serviceName}`" /tr `"$cmdFile`""
Stopping and deleting the task enables us to reinstall.
$packageName = 'myproject'
$serviceName = 'My Project'
$installDir = "c:\examples"
$packageDir = "$installDir\my_project"
if (Test-Path -path $packageDir) {
Write-Host "Stopping and deleting current version of ${packageName}"
Start-ChocolateyProcessAsAdmin "schtasks /delete /f /tn `"${serviceName}`" "
Start-Sleep 2
Start-ChocolateyProcessAsAdmin "schtasks /end /f /tn `"${serviceName}`" "
Remove-Item -recurse $(Join-Path $packageDir "\*") -exclude *.conf, *-bak*, *-old*
}
tl;dr
Putting it all together looks like this:
$ErrorActionPreference = 'Stop'; # stop on all errors
$packageName = 'myproject'
$serviceName = 'My Project'
$installDir = "c:\examples"
$packageDir = "$installDir\my_project"
$cmdFile = "$packageDir\$packageName.cmd"
$currentDatetime = Get-Date -format yyyyddMMhhmm
$scriptDir = "$(Split-Path -parent $MyInvocation.MyCommand.Definition)"
$installFile = (Join-Path $scriptDir -ChildPath "..\archives\$packageName.jar") | Resolve-Path
if (Test-Path -path $packageDir) {
Write-Host "Stopping and deleting current version of ${packageName}"
Start-ChocolateyProcessAsAdmin "schtasks /delete /f /tn `"${serviceName}`" "
Start-Sleep 2
Start-ChocolateyProcessAsAdmin "schtasks /end /f /tn `"${serviceName}`" "
Remove-Item -recurse $(Join-Path $packageDir "\*") -exclude *.conf, *-bak*, *-old*
Write-Host $(Get-Service "$serviceName" -ErrorAction SilentlyContinue).Status
if ($(Get-Service "$serviceName" -ErrorAction SilentlyContinue).Status -eq "Running") {
Write-Host "Stopping and deleting current version of ${packageName}"
Start-ChocolateyProcessAsAdmin "Stop-Service `"${serviceName}`""
Start-Sleep 2
}
if ($(Get-Service "$serviceName" -ErrorAction SilentlyContinue).Status -ne "Running") {
Write-Host "Cleaning ${packageDir} directory"
Remove-Item -recurse $(Join-Path $packageDir "\*") -exclude *.conf, *-bak*, *-old*
}
}
Write-Host "Making sure $installDir is in place"
if (!(Test-Path -path $installDir)) {New-Item $installDir -Type Directory | Out-Null}
Write-Host "Making sure $packageDir is in place"
if (!(Test-Path -path $packageDir)) {New-Item $packageDir -Type Directory | Out-Null}
Write-Host "Installing ${packageName} to ${packageDir}"
Copy-Item $installFile $packageDir
if (!(Test-Path ($cmdFile)))
{
$cmdcontent = @"
cd /d ${packageDir}
java -jar ${packageName}.jar >> output.log 2>&1
"@
echo "Dropping a ${packageName}.cmd file"
Set-Content $cmdFile $cmdcontent -Encoding ASCII -Force
}
if (!(Get-Service "${serviceName}" -ErrorAction SilentlyContinue))
{
echo "No ${serviceName} Service detected"
echo "Installing ${serviceName} Service"
Start-ChocolateyProcessAsAdmin "install `"${serviceName}`" ${cmdFile}" nssm
}
Start-ChocolateyProcessAsAdmin "set `"${serviceName}`" Start SERVICE_DEMAND_START" nssm
echo "Installing ${serviceName} Task"
Start-ChocolateyProcessAsAdmin "schtasks /create /f /ru system /sc hourly /st 00:30 /tn `"${serviceName}`" /tr `"$cmdFile`""
Finally
Now we just need to create the package in our build script. The package will be named my_project.version.nupkg.
On our build machine we need to install choco. On the target machine we need the following tools installed:
chocolatey and nssm (for service management). Now we can create the package with:
choco pack --version=${version}
Copy it to the target machine and install the current version with:
choco install -f -y c:\\installations\\${archive.name} --version=${version}
Put these steps inside a build script and use your favourite contininuous integration platform and voila.
Done.