Marching squares is an algorithm to find the contour of a scalar field. For example, that can be a height-map and the resulting contour would be lines of a specific height known as ‘isolines’.
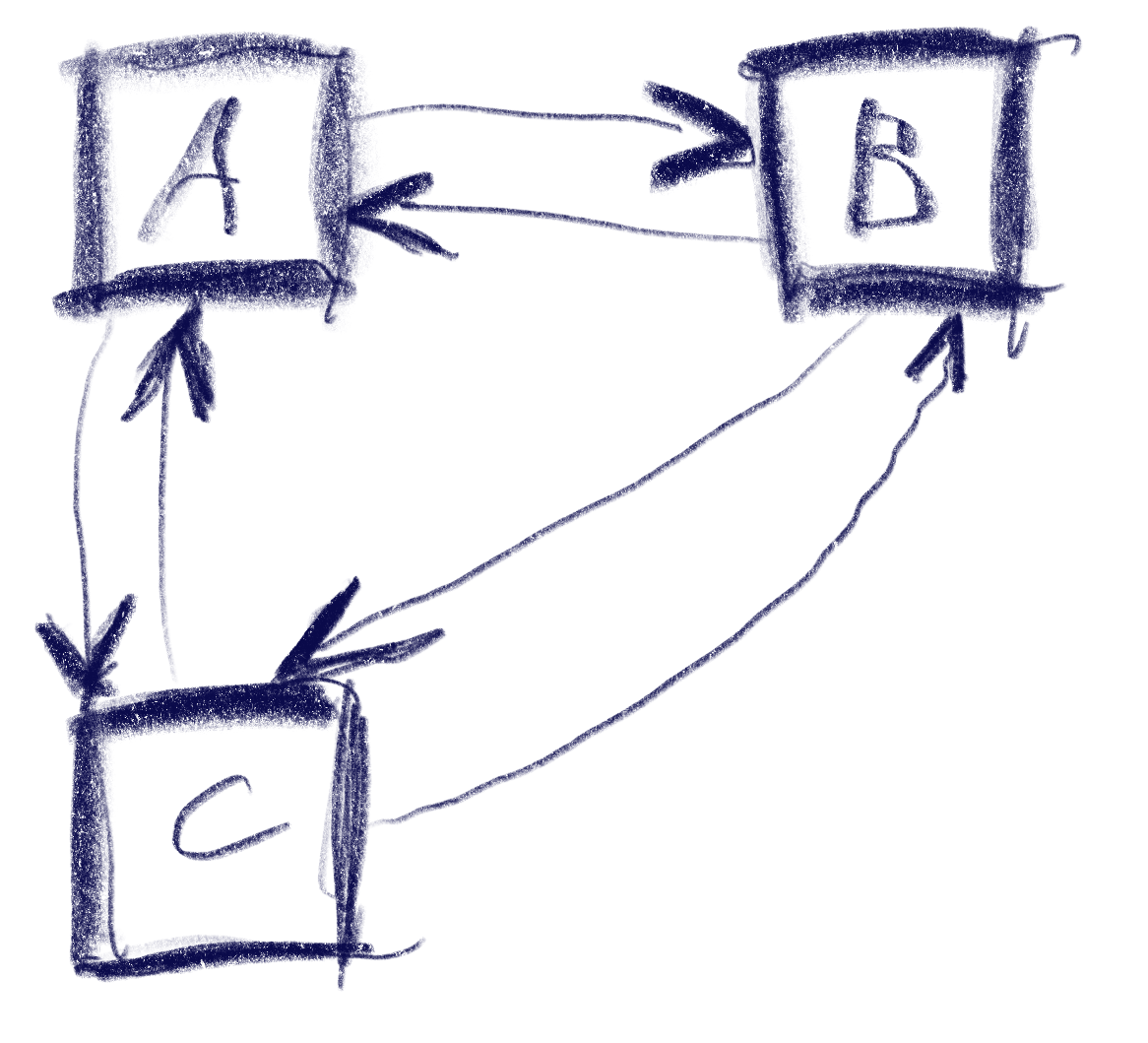
At the core of the algorithm is a lookup table that says which line segments to generate for a specific ’tile’ configuration. To make sense of that, you start with a convention on how your tile configuration and the resulting lines are encoded. I typically add a small piece of ASCII-art to explain that:
// c3-e3-c2
// | |
// e0 e2
// | |
// c0-e1-c1
//
// c are corner bits, e the edge indices
The input of our lookup table is a bitmask of which of the corners c are ‘in’ or above our isolevel. The output is which tile edges e to connect with line segments. That is either 0, 1 or 2 line segments, so we need to encode that many pairs. You could easily pack that into a 32-bit, but I am using a std::vector<std::uint8_t> for simplicity. Here’s the whole thing:
using config = std::vector<std::uint8_t>;
using config_lookup = std::array<config, 16>;
const config_lookup LOOKUP{
config{},
{ 0, 1 },
{ 1, 2 },
{ 0, 2 },
{ 2, 3 },
{ 0, 1, 2, 3 },
{ 1, 3 },
{ 0, 3 },
{ 3, 0 },
{ 3, 1 },
{ 1, 2, 3, 0 },
{ 3, 2 },
{ 2, 0 },
{ 2, 1 },
{ 1, 0 },
config{},
};
I usually want to generate index meshes, so I can easily connect edges later without comparing the floating-point coordinates. So one design goal here was to generate each point only once. Here is the top-level algorithm:
using point_id = std::tuple<int, int, bool>;
std::vector<v2<float>> points;
// Maps construction parameters to existing entries in points
std::unordered_map<point_id, std::uint16_t, key_hash> point_cache;
// Index pairs for the constructed edges
std::vector<std::uint16_t> edges;
auto [ex, ey] = map.size();
auto hx = ex-1;
auto hy = ey-1;
// Construct inner edges
for (int cy = 0; cy < hy; ++cy)
for (int cx = 0; cx < hx; ++cx)
{
std::uint32_t key = 0;
if (map(cx, cy) > threshold)
key |= 1;
if (map(cx + 1, cy) > threshold)
key |= 2;
if (map(cx + 1, cy + 1) > threshold)
key |= 4;
if (map(cx, cy + 1) > threshold)
key |= 8;
auto const& geometry = LOOKUP[key];
for (auto each : geometry)
{
auto normalized_id = normalize_point(cx, cy, each);
auto found = point_cache.find(normalized_id);
if (found != point_cache.end())
{
edges.push_back(found->second);
}
else
{
auto index = static_cast<std::uint16_t>(points.size());
points.push_back(build_point(map, threshold, normalized_id));
edges.push_back(index);
point_cache.insert({ normalized_id, index });
}
}
}
For each tile, we first figure out the lookup input-key by testing the 4 corners. We then get-or-create the global point for each edge point from the lookup.
Since each edge in a tile can be accessed from two sides, we first normalize it to have a unique key for our cache:
point_id normalize_point(int cx, int cy, std::uint8_t edge)
{
switch (edge)
{
case 3:
return { cx, cy + 1, false };
case 2:
return { cx + 1, cy, true };
default:
return { cx, cy, edge == 0 };
};
}
When we need to create a point an edge, we interpolate to estimate where exactly the isoline intersects our tile-edge:
v2<float> build_point(raster_adaptor const& map, float threshold, point_id const& p)
{
auto [x0, y0, vertical] = p;
int x1 = x0, y1 = y0;
if (vertical)
y1++;
else
x1++;
const auto s = map.scale();
float h0 = map(x0, y0);
float h1 = map(x1, y1);
float lambda = (threshold - h0) / (h1 - h0);
auto result = v2{ x0 * s, y0 * s };
auto shift = lambda * s;
if (vertical)
result[1] += shift;
else
result[0] += shift;
return result;
}
For a height-map, that’s about as good as you can get.
You can, however, sample other scalar field functions with this as well, for example sums of distances. This is not the most sophisticated implementation of marching squares, but it is reasonably simple and can easily be adapted to your needs.