So, I have one PyQt application which not only is quite data-heavy, but also has significant real-time requirements, as well as multiple windows. This construct brings some absolutely horrifying highly intellectually inspiring quests with it, and Python turned out to be kind of a good decision for that project, because that is one of the languages where, when you think about your structure a bit, you might get to write very natural-sounding like code.
Of course, the following idea is actually language-agnostic, I will just use fictive Python examples close to problems-based-on-a-true-story.
This in itself is not only a matter of aesthetics, but because real-time demands are quite tricky to reliably be covered by unit tests alone, the actual code has to read itself so clearly that one does not need to second-guess what any of this does. Think of a bedtime story, which usually would not, coming to think of it, contain clauses – or paragraphs, for that matter – requiring, under circumstances not even trivial to the human eye, one kind of meticulous gymnastics, easily negating twice, or thrice, and relying on Python’s borderline criminal degrees of freedom in duck typing, or canards even– you see — your toddler will now not go to sleep anytime soon. Or trust you with another story, for that matter.
Now I found out: While Qt is somewhat mature, one cannot even trust their way of doing things – i.e. turns out, the signals/slots system is not particularly designed for performance. Neither did I feel inclined to put my faith into even another state management solution like e.g. python-statemachine package, because – as capable as that sounds, it might be overkill, and distracting with its own idiosyncrasies (as also: I would not recommend Redux for a web project anymore, especially in TypeScript, except for you really know from the start that this is a good fit).
But, so, I have some tricky interplays between
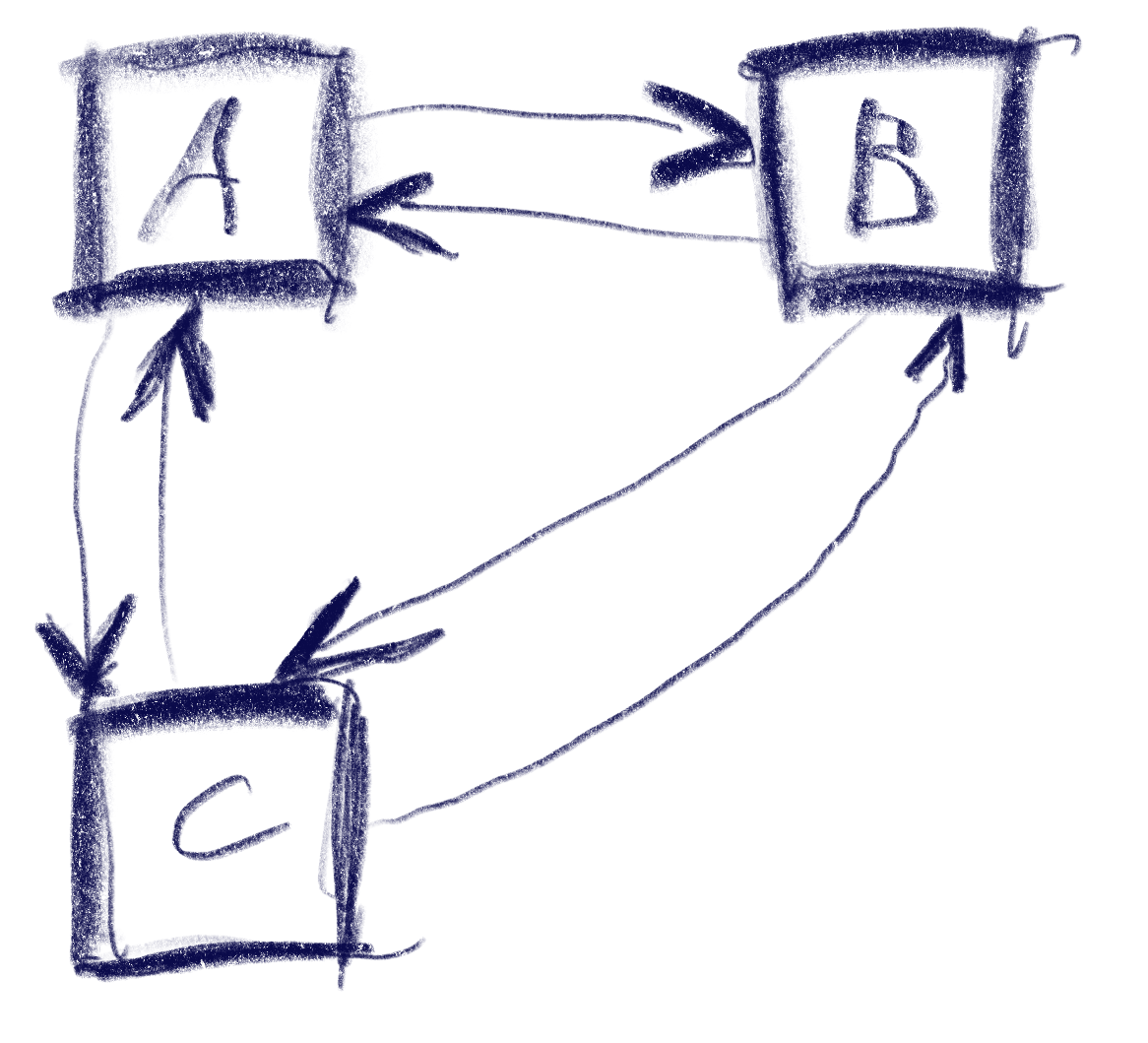
- Data consistency / single-source-ness demands that e.g. between two windows, there should only be primitive data exchanged, say str/int identifiers, and both have access to their repositories; not throwing loaded data sets around my memory in order to go stale at times
- Comprehension, most significantly Single Level of Abstraction, or other indicators of mental load like how many levels of intendation / return paths are mixed within sight (and also, Type Annotations do help a lot in Python, even though not mandatory, i.e. the complete opposite of fighting Redux-TypeScript-chimaeras – but I digress…
- Robustness, where I would believe that my user (me) has virtually no chance of even seeing this and that window when their data is maybe still loading somewhere – but I still check these cases, because this bedtime story has no business in leaving you an hopeful-to-anxious pile of nerves
- Traceability of your state, for troubleshooting and useful UI feedback (as you’d guess, real-time event based stuff is not easily debugged by break points or logging alone).
So over months in that project, I grew annoyed of code like (Symbolbild)
class Editor:
# ...
def load_editor(self, params: Optional[EditorParams]):
if params and (self._entity is not None or
self._entity.id != params.id):
if entity := repository.load_entity(params.id):
self._entity = entity
else:
raise ValueError("repository needs some alone time :(")
self._entity.other_stuff = other_repo.check_stuff()
elif params is None:
raise TypeError(
"sounds Optional in our signature, but actually is not"
)
elif self._entity.id == params.
self.adjust_more_stuff(self._entity, params.stuff)
# ...Because encountering any single block of these drags you down, I have currently accustomed myself to write these as (one can argue whether the names like “Supplier” are the best here, but they’re not the worst, I believe)
@dataclass(frozen=True)class LoadedEntity: id: str entity: Optional[Entity] stuff: Optional[OtherStuff] @property def is_unusable(self): return self.entity is None @property def missing_stuff(self): if self.is_unusuable: return True else: return self.stuff is Noneclass EntitySupplier: _current: LoadedEntity _entity_repo: EntityRepository _stuff_repo: OtherStuffRepo # __init__ etc. hereby left out as boilerplate def load_params(self, params: Any): # do all your checks in here if (... very bad ...): self._current = LoadedEntity(params.id, None) return entity = self._entity_repo.get(params.id) stuff = self._stuff_repo.get(params.stuff).for(entity) return LoadedEntity( params.id, entity, stuff ) @property def entity(self): return self._current.entity def expecting(self, stuff: bool = False) -> Optional[LoadedEntity]: if stuff and self._current.missing_stuff: return None return self._current class Editor: _supply: EntitySupplier _logger: SomeLogger def __init__(self, **kwargs): self._supply = EntitySupplier(**kwargs) self._logger = BlaBlaLogger() def load(self, params): self._supply.load_params(params) if entity := self._supply.entity: self.update_ui(entity) else: self._logger.error("Outsmarted, eh? %s | %s", str(params), stack_trace()) return if supply := self._supply.expecting(stuff=True): self.initiate_stuff_from(supply) else: self._logger.info("Entity %s is ready, Stuff is not | %s", str(entity), stack_trace())
So, the LoadedEntity serves like a concatenation of several Optional types, but it wraps the logic (i.e. there’s no sense in having stuff when you don’t have entity first) instead of just shruggingly claming “well, this entity here is optional – and that other stuff is, too”. Now, LoadedEntity is not a pretty name at all (have a better one?), but it sure beats having two straightaway lies.
I like that pattern because it allows me to stash the EntitySupplier and LoadedEntity somewhere on their own (I do strictly not believe that every class needs its own file, but some of the “Single …” ideas (Responsibility, Level of Abstraction, you name it) do also apply here; and the Editor.load(…) itself does read somewhat like a short story. It has quite linear structure and can early-return, and/or log, on demand, and while naming is still hard (consistently voted one half of famous Hard Things), I could even have some fun in designing that language while preserving the idea, that future-me can arrive in a few weeks (read: hours) and still trust in some of the entites and stuff.
The quintessence here is: Checking for None (which is Python’s NULL, and the typing Optional[T] is identically equal to T | None) is still a thing in 2026 due to its sheer practicality, but if you design some some structure around that and keep these checks in something like LoadedEntity, you can keep the abyss from staring back into you.