
In my last post, I showed how to generate an icosphere, a subdivided icosahedron, without any fancy data-structures like the half-edge data-structure. Someone in the reddit discussion on my post mentioned that a spherified cube is also nice, especially since it naturally lends itself to a relatively nice UV-map.
The old algorithm
The exact same algorithm from my last post can easily be adapted to generate a spherified cube, just by starting on different data.

After 3 steps of subdivision with the old algorithm, that cube will be transformed into this:

Slightly adapted
If you look closely, you will see that the triangles in this mesh are a bit uneven. The vertical lines in the yellow-side seem to curve around a bit. This is because unlike in the icosahedron, the triangles in the initial box mesh are far from equilateral. The four-way split does not work very well with this.
One way to improve the situation is to use an adaptive two-way split instead:
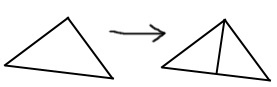
Instead of splitting all three edges, we’ll only split one. The adaptive part here is that the edge we’ll split is always the longest that appears in the triangle, therefore avoiding very long edges.
Here’s the code for that. The only tricky part is the modulo-counting to get the indices right. The vertex_for_edge function does the same thing as last time: providing a vertex for subdivision while keeping the mesh connected in its index structure.
TriangleList
subdivide_2(ColorVertexList& vertices,
TriangleList triangles)
{
Lookup lookup;
TriangleList result;
for (auto&& each:triangles)
{
auto edge=longest_edge(vertices, each);
Index mid=vertex_for_edge(lookup, vertices,
each.vertex[edge], each.vertex[(edge+1)%3]);
result.push_back({each.vertex[edge],
mid, each.vertex[(edge+2)%3]});
result.push_back({each.vertex[(edge+2)%3],
mid, each.vertex[(edge+1)%3]});
}
return result;
}
Now the result looks a lot more even:

Note that this algorithm only doubles the triangle count per iteration, so you might want to execute it twice as often as the four-way split.
Alternatives
Instead of using this generic of triangle-based subdivision, it is also possible to generate the six sides as subdivided patches, as suggested in this article. This approach works naturally if you want to have seams between your six sides. However, that approach is more specialized towards this special geometry and will require extra “stitching” if you don’t want seams.
Code
The code for both the icosphere and the spherified cube is now on github: github.com/softwareschneiderei/meshing-samples.






