
The jenkins continuous integration (CI) server provides several ways to trigger builds remotely, for example from a git hook. Things are easy on an open jenkins instance without security enabled. It gets a little more complicated if you like to protect your jenkins build environment.
Git plugin notify commit url
For git there is the “notifyCommitUrl” you can use in combination with the Poll SCM settings:
$JENKINS_URL/git/notifyCommit?url=http://$REPO/project/myproject.git
Note two things regarding this approach:
- The url of the source code repository given as a parameter must match the repository url of the jenkins job.
- You have to check the
Poll SCMsetting, but you do not need to provide a schedule
Another drawback is its restriction to git-hosted jobs.
Jenkins remote access api
Then there is the more general and more modern jenkins remote access api, where you may trigger builds regardless of the source code management system you use.
curl -X POST $JENKINS_URL/job/$JOB_NAME/build?token=$TOKEN
It allows even triggering parameterized builds with HTTP POST requests like:
curl -X POST $JENKINS_URL/job/$JOB_NAME/build \
--user USER:TOKEN \
--data-urlencode json='{"parameter": [{"name":"id", "value":"123"}, {"name":"verbosity", "value":"high"}]}'
Both approaches work great as long as your jenkins instance is not secured and everyone can do everything. Such a setting may be fine in your companies intranet but becomes a no-go in more heterogenious environments or with a public jenkins server.
So the way to go is securing jenkins with user accounts and restricted access. If you do not want to supply username/password as part of the url for doing HTTP BASIC auth and create users just for your repository triggers there is another easy option:
Using the Build Authorization Token Root Plugin!
Build authorization token root plugin
The plugin introduces a configuration setting in the Build triggers section to define an authentication token:
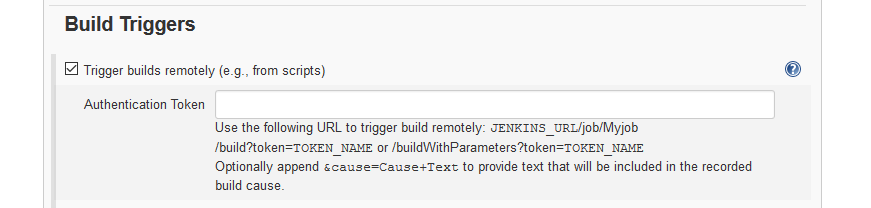
It also exposes a url you can access without being logged in to trigger builds just providing the token specified in the job:
$JENKINS_URL/buildByToken/build?job=$JOB_NAME&token=$TOKEN
Or for parameterized builds something like:
$JENKINS_URL/buildByToken/buildWithParameters?job=$JOB_NAME&token=$TOKEN&Type=Release
Conclusion
The token root plugin does not need HTTP POST requests but also works fine using HTTP GET. It does neither requires a user account nor the awkward Poll SCM setting. In my opinion it is the most simple and pragmatic choice for build triggering on a secured jenkins instance.


")
