
In Part 1, I explained how algebra can shed some light on a quite restricted class of react-apps. Today, I will lift one of the restrictions. This step needs a new kind of algebraic structure:
Categories
Category theory is a large branch of pure mathematics, with many facets and applications. Most of the latter are internal to pure mathematics. Since I have a very special application in mind, I will give you a definition which is less general than the most common ones.
Categories can be thought of as generalized monoids. At the same time, a Category is a labelled, directed multigraph with some extra structure. Here is a picture of a labelled directed multigraph – its nodes are labelled with upper case letters and its edges are labelled with lower case letters:
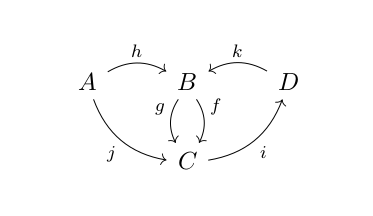
If such a graph happens to be a category, the nodes are called objects and the edges morphisms. The idea is, that the objects are changed or morphed into other objects by the morphisms. We will write 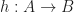


But I said something about extra structure and that categories generalize monoids. This extra structure is essentially a monoid structure on the morphisms of a category, except that there is a unit for each object called identity and the operation “
Note that “
For the indentities and the operation “
Definition (not as general as it could be…)
A category consists of the following data:
- A set of objects A,B,…
- A set of morphisms
- An operation “
and
returns a morphism
- For any object a morphism

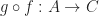

Such that the following laws hold:
- “
,
and
, we have:
- The identities are left and right neutral: For all morphisms
we have:
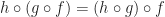
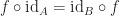
Examples
Before we go to our example of interest, let us look at some examples:
- Any monoid is a category with one object O and for each element m of the monoid a morphism
. “
” is defined to be
.
- The graph below can be extended to a category by adding the morhpisms
and an identity for
is
.
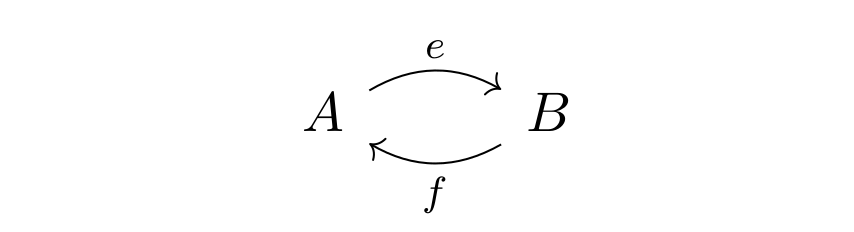
- More generally: Let
be a labelled directed graph with edges
and nodes
. Then there is a category
with objects
Action Categories
So let’s generalize Part 1 with our new tool. Our new scope are react-apps, which have actions without parameters, but now, action can not neccessarily be applied in any order. If an action can be fired, may now depend on the state of the app.
The smallest example I can think of, where we can see whats new, is an app with two states, let’s call them ON and OFF and two actions, let’s say SWITCH_ON and SWITCH_OFF:
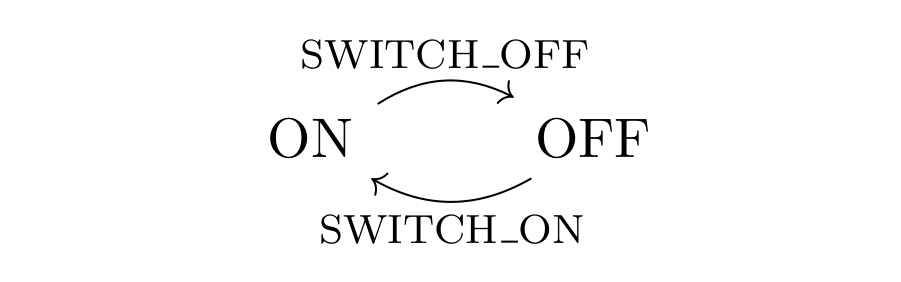
Let us also say, that the action SWITCH_ON can only be fired in state OFF and SWITCH_OFF only in state ON. The category for that graph has as its morphims the possible sequences of actions. Now, if we follow the path of part 1, the obvious next step is to say that SWITCH_ON after SWITCH_OFF (and the other way around) is the same as the empty action-sequence — which leads us to…
Quotients
We made a pretty hefty generalization from monoids to categories, but the theory for quotients remains essentially the same. As we defined equivalence relations on the elements of a monoid, we can define equivalence relations on the morphisms of a category. As last time, this is problematic in general, but turns out to just work if we replace sequences of morphisms in the action category with matching source and target.
So in the example above, it is ok to say that SWITCH_ON SWITCH_OFF is the empty sequence on ON and SWITCH_OFF SWITCH_ON is the empty sequence on OFF (keep in mind that the first action to be executed is on the right). Then any action sequence can be reduced to simply SWITCH_ON, SWITCH_OFF or an empty sequence (not the empty sequence, because we have two of them with different source and target). And in this case, the quotient category will be what we drew above, but as a category.
Of course, this is not an example where any high-powered math is needed to get any insights. So far, these posts where just about understanding how the math works. For the next part of this series, my plan is to show how existing tools can be used to calculate larger examples.
 ” satisfying these two laws:
” satisfying these two laws:

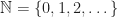 with addition.
with addition.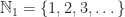 with multiplication.
with multiplication.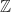 with addition.
with addition.![[1,2,3,\dots]](https://s0.wp.com/latex.php?latex=%5B1%2C2%2C3%2C%5Cdots%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
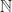 with addition and List({1}) are of the same form, witnessed by the following renaming scheme:
with addition and List({1}) are of the same form, witnessed by the following renaming scheme:![0 \mapsto []](https://s0.wp.com/latex.php?latex=0+%5Cmapsto+%5B%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![1 \mapsto [1]](https://s0.wp.com/latex.php?latex=1+%5Cmapsto+%5B1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![2 \mapsto [1,1]](https://s0.wp.com/latex.php?latex=2+%5Cmapsto+%5B1%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![3 \mapsto [1,1,1]](https://s0.wp.com/latex.php?latex=3+%5Cmapsto+%5B1%2C1%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

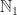 , the integers and the monoid of maps on a set, all of the examples above are free monoids. There is also a nice abstract definition of “free”, but for the purpose at hand to describe a special kind of monoid, it is good enough to say, that a monoid M is free, if there is a set A such that M is of the form List(A).
, the integers and the monoid of maps on a set, all of the examples above are free monoids. There is also a nice abstract definition of “free”, but for the purpose at hand to describe a special kind of monoid, it is good enough to say, that a monoid M is free, if there is a set A such that M is of the form List(A). I
I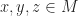 be elements of a monoid
be elements of a monoid  with operation “
with operation “ is identified with
is identified with 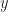 . Then, denoting equivalence classes with
. Then, denoting equivalence classes with ![[\_]](https://s0.wp.com/latex.php?latex=%5B%5C_%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) it is not clear if
it is not clear if ![[x] \cdot [y]](https://s0.wp.com/latex.php?latex=%5Bx%5D+%5Ccdot+%5By%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) should be defined to be
should be defined to be ![[x\cdot z]](https://s0.wp.com/latex.php?latex=%5Bx%5Ccdot+z%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) or
or ![[y\cdot z]](https://s0.wp.com/latex.php?latex=%5By%5Ccdot+z%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. 