Once every while, I remember a public software engineering talk, held by Daniel and visited by me (not only), at a time before I accidentally started working for the Softwareschneiderei for several years, which turned out splendid – but I digress – and while the topic of that talk was (clearly) a culinary excursion about… how onions are superior to spaghetti… one side discussion spawned that quote (originally attributed to Michael Jackson e.g. here)
You know the First Rule of Optimization?
… don’t.
You know the Second Rule?
… don’t do it YET.
I like that a lot, because while we’ve all been at places where we knew a certain algorithm to be theoretically sub-optimal, measures of optimal is also “will it make my customer happy in a given time” and “will our programming resources be used at the most effective questions at hand”.
And that is especially tricky in software in which a customer starts with a wish like “I want a certain view on my data that I never had before” (thinking of spreadsheets, anyone?) and because they do not know what they will learn from that, no specification can even be thought-out. Call it “research” or “just horsing around”, but they will be thankful if you have a robust software that does the job, and customers can be very forgiving about speed issues, especially when they accumulate slowly over time.
Now we all know what N+1 query problems are (see e.g. Frederik’s post from some weeks ago), and even without databases, we are generally wary about any nested loops. But given the circumstances, one might write specific queries where you do allow yourself some.
There it not only “I have no time”. Sometimes you can produce much more readable code by doing nested queries. It can make sense. I mean, LINQ and the likes have a telling appearance, e.g. one can read
var plansForOffer = db.PlansFor(week).Where(p => p.Offers.Contains(offer.Id));
if (plansForOffer.Any()) {
lastDay = plansForOffer.Max(p => p.ProposedDay);
}surely quite well; but here alone do the .Any() and the .Max() loop over similar data needlesly, and probably the helper PlansFor(…) does something like it, and then run that in a loop over many “offers” and quickly, there goes your performance down the drain only because your customers have now 40 instead of 20 entities.
To cut a long story short – with given .NET and Entity Framework in place, and in the situation of now-the-customer-finds-it-odd-that-some-queries-take-seven-minutes-to-completion, I did some profiling. In software where there are few users and ideally one instance of the software on one dedicated machine, memory is not the issue. So I contrasted the readable, “agile” version with some queries at startup and converged at the following pattern
var allOffers = await db.Offers
.Where(o => ... whatever interests you ... )
.Include(o => ... whatever EF relations you need ...)
.ToListAsync();
var allOfferIds = allOffsets
.Select(o => o.Id)
.ToArray();
var allPlans = await db.PlanningUnits
.Where(p => p.Contains(offer.Id))
.AsNoTracking()
.ToListAsync();
var allPlanIds = allPlans
.Select(p => p.Id)
.ToArray();
var allAppointments = await db.Appointments
.Where(a => allPlanIds.Contains(a.PlanId))
.AsNoTracking()
.ToListAsync();
var requiredSupervisors = allAppointments
.Select(a => a.Supervisor)
.Distinct()
.ToArray();
var requiredRooms = await db.Rooms
.Where(r => requiredSupervisors.Contains(r.SupervisorId)
.AsNoTracking()
.ToDictionaryAsync(r => r.Id);
// ...
return (
allOffers
.Select(o => CollectEverythingFromMemory(o, week, allOffers, allPlans, allAppointments, ...))
.ToDictionary(o => o.Id);
);
So the patterns are
- Collect every data pool that you will possibly query as completely as you need
- Load it into memory as .ToList() and where you can – e.g. in a server application, use await … .ToListAsync() in order to ease the the request thread pool
- With ID lists and subsequent .Contains(), the .ToArray() call is even enough as arrays come with less overhead – although this is less important here.
- Use .ToDictionaryAsync() for constant-time lookups (although more modern .NET/EF versions might have advanced functions there, this is the more basic fallback that worked for me)
- Also, note the .AsNoTracking() where you are querying the database only (if not mutating any of this data), so EF can save all the memory overhead.
With that pattern, all inner queries transform to quite efficient in-memory-filtering of appearance like
var lastDay = allPlans
.Where(p => p.Week == week
&& allPlanIds.Contains(p.Id)
&& planOfferIds.Contains(offer.Id)
)
.Max(p => p.ProposedDay);and while this greatly blew up function signatures, and also required some duplication because these inner functions are not as modular, as stand-alone anymore, our customers now enjoyed a reduction in query size of really
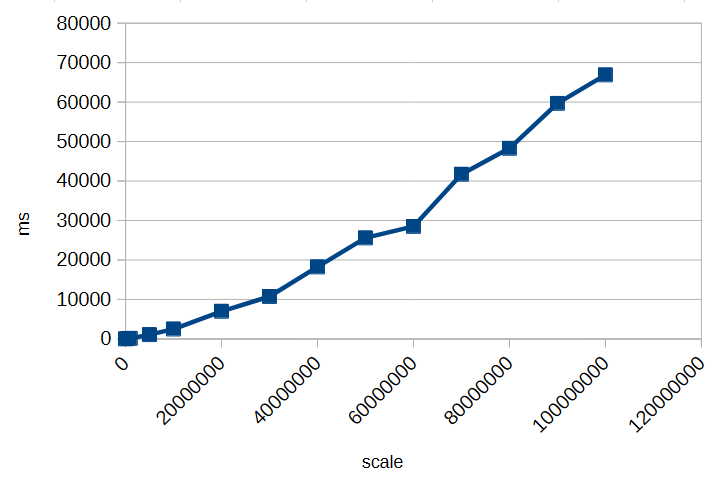
- Before: ~ 7 Minutes
- After: ~ half a second
i.e. a 840-fold increase in performance.
Conclusion: not regretting much
It is somewhat of a dilemma. The point of “optimization…? don’t!” in its formulation as First and Second Rule holds true. I would not have written the first version of the algorithm in that consolidated .ToList(), .ToArray()., ToDictionary() shape when still in a phase where the customer gets new ideas every few days. You will need code that is easier to change, and easier to reckon about.
By the way – cf. the source again – ,the Third Rule is “Profile Before Optimizing”. When dealing with performance, it’s always crucial to find the largest culprit first.
And then, know that there are general structures which make such queries efficient. I can apply these thoughts to other projects and probably do not have to finely dig into the exact details of other algorithms, I just need to make that trade-off above.