
It is said that source code gets read a hundred times more often than it gets written. My experience confirms this circumstance, which leads to a principle of economic source code modifications: The first modification is almost for free, it’s the later ones that run up a bill. In order to achieve a low TCO (total cost of ownership), it’s sound advice to plan (and develop) for easy maintenance instead of easy production. This principle even has a fancy name: Keep It Simple, Stupid (KISS).
Origin of KISS
According to the english Wikipedia on the topic, the principle’s name was coined by an aircraft engineer named Kelly Johnson, who also designed the fastest jet plane of all time, the SR-71 “Blackbird”. The aircraft reached speeds of over Mach 3 and had an unmatched defensive armament: enough thrust to evade any confrontation. It would simply fly higher and/or faster than anything launched against it, like interceptor fighters or anti-air missiles. The Blackbird used construction material that was specifically invented for this plane and very expensive, so it definitely was no easy production. Sadly for this blog post, it wasn’t particularly easy to maintain, either. It usually leaked so much fuel that it had to be refueled directly after takeoff. The leaks were pragmatically designed that way and would seal themselves in flight. It’s quite an interesting plane.
Easy maintenance
Johnson once alledegly gave his engineers a bunch of tools and required that the aircraft under design must be repairable with only these tools, by an average mechanic in the field under combat conditions (e.g. stressed, exhausted and narrow timeframe). This is a wonderful concept that I regularly apply to my projects: Imagine that you are on-site with your customer, the most important functionality of your project just broke, resulting in a disastrous standstill of the whole facility and all you have is your sourcecode and the vi editor (or vim, if you’re non-hardcore like me). No internet, no IDE, no extensive documentation. Could you make meaningful changes to your project under these conditions? What needs to be changed to make your life easier in such an extreme situation? What restrictions would these changes impose on your daily work? How much effort/damage/resources would these changes cost? Is it easier to anticipate maintenance or to trust to luck that it won’t be necessary?
Easy production
A while ago, I reviewed the code of a map tool. The user viewed a map and could click on it to mark a certain location. The geo coordinates of this location would be used as an input for further computations. The map was restricted to a fixed area, so the developer wrote the code in the easiest way possible: He chose well-known geographic landmarks on the map and determined their geo coordinates and pixel locations. 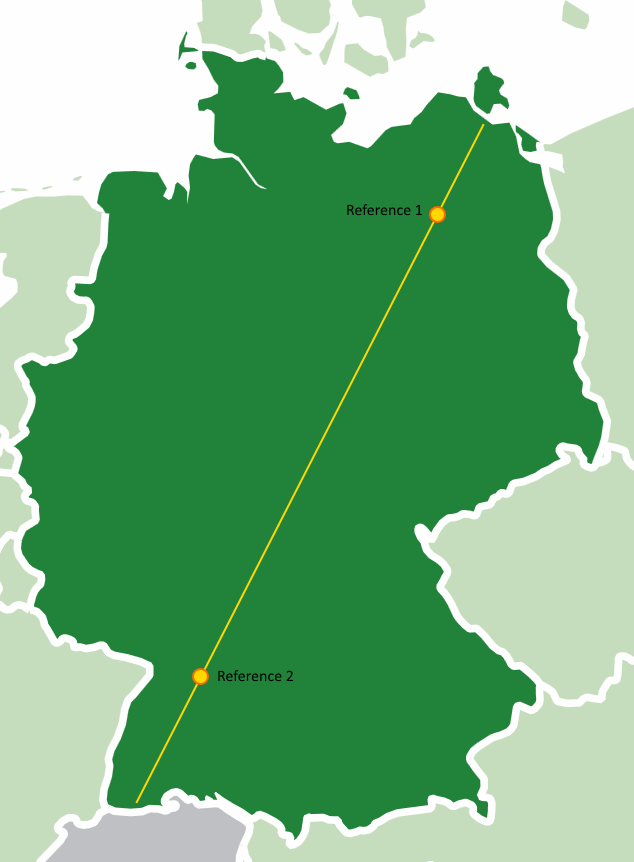 Those were the reference points in the code that every click would be related to. Using easy mathematic (rule of three), each point on the map could be calculated. Clever trick and totally working! The code practically wrote itself and the reference points only needed to be determined once.
Those were the reference points in the code that every click would be related to. Using easy mathematic (rule of three), each point on the map could be calculated. Clever trick and totally working! The code practically wrote itself and the reference points only needed to be determined once.
Until the map was changed. The code contained some obscure constants that described the original landmarks, but the whole concept of arbitrary reference points was alien to the next developer. He was used to the classic concept of two reference points: top left and bottom right, with their respective geo coordinates and pixel locations. What seemed like a quick task turned into a stressful reclaiming of the clever trick during production.
In this example, the production (initial development) was easy, straight-forward and natural, but not easily reproducible during the maintenance phase (subsequent modification). The algorithm used a clever approach, but this cleverness isn’t necessarily available “under combat conditions”.
Go the extra mile
Most machines are designed so that wearing parts can be easily replaced. Think of batteries in electronic gagdets (well, at least before the gadget’s estimated lifetime was lower than the average battery life) or light bulbs in cars (well, at least before LED headlights were considered cool). Thing is, engineers usually know the wear effects their designs have to endure. There is no “usual wear effect” on software, due to lack of natural forces like gravitation. Everything could change, so it’s better to be prepared for all sorts of change. That’s the theory, but it’s not economically sound to develop software that is prepared for any circumstance. Pragmatic reasoning calls for compromise, like supporting changes that
- are likely to happen (this needs to be grounded in domain knowledge and should be documented in the code)
- are not expensive to arrange beforehands (the popular “low-hanging fruits”)
- are expensive to implement afterwards
The last aspect might be a bit of a surprise, but it’s the exact aspect that came to play in the example above: To recreate the knowledge about the clever trick of landmark choices needed more time than implementing the classic interpolation taking the edge points.
So if you see a possible (and not totally unlikely) change that will be expensive to implement once the intimate knowledge of the code you have during the initial development, go the extra mile and prepare for it right now. Leave a comment, implement some kind of extension mechanism or just mind the code seams. In our example, slightly complicating the initial development led to a dramatically less clever and more accessible code.
Conclusion
You should consider writing your code for easy maintenance, even if that means additional effort during the initial implementation. Imagine that you yourself have to do the future change, stressed, over-worked and under time pressure, without any recollection about your thoughts today, lacking your familiar tools while your customer waits impatiently by your side. With proper preparation, even this scenario is feasible.


