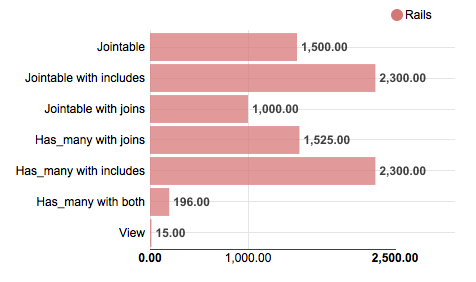
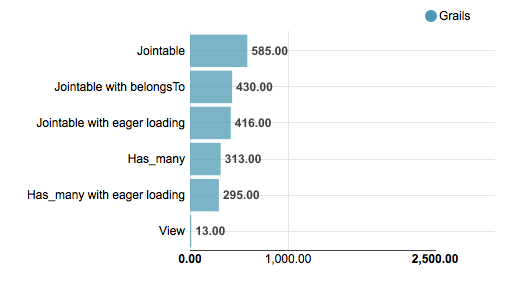
Tips for a better performance like using views or reducing the complexity of your algorithms only help when you know where you can improve performance. So to find the places where speed is needed you can build extensive load and performance tests or even better you can monitor the performance of your app in production. Many solutions exists which give you varying levels of detail (the costs of them also varies). But often a simple solution is enough. We start with a typical (CRUD) web app and build a monitor and a tool to analyse response times. The goal is to see what are the ten worst performing queries of the last week. We want an answer to this question continuously and maybe ask additional questions like what were the details of the responses like user/role, URL, max/min, views or persistence. A web app built on Rails gives us a lot of measurements we need out of the box but how do we extract this information from the logs?
Typical log entries from an app running on JRuby on Rails 4 using Tomcat looks like this:
Sep 11, 2014 7:05:29 AM org.apache.catalina.core.ApplicationContext log
Information: I, [2014-09-11T07:05:29.455000 #1234] INFO -- : [19e15e24-a023-4a33-9a60-8474b61c95fb] Started GET "/my-app/" for 127.0.0.1 at 2014-09-11 07:05:29 +0200
...
Sep 11, 2014 7:05:29 AM org.apache.catalina.core.ApplicationContext log
Information: I, [2014-09-11T07:05:29.501000 #1234] INFO -- : [19e15e24-a023-4a33-9a60-8474b61c95fb] Completed 200 OK in 46ms (Views: 15.0ms | ActiveRecord: 0.0ms)
Important to identify log entries for the same request is the request identifier, in our case 19e15e24-a023-4a33-9a60-8474b61c95fb. To see this in the log you need to add the following line to your config/environments/production.rb:
config.log_tags = [ :uuid ]
Now we could parse the logs manually and store them in a database. That’s what we do but we use some tools from the open source community to help us. Logstash is a tool to collect, parse and store logs and events. It reads the logs via so called inputs, parses, aggregates and filters with the help of filters and stores by outputs. Since logstash is by Elasticsearch – the company – we use elasticsearch – the product – as our database. Elasticsearch is a powerful search and analytcs platform. Think: a REST frontend to Lucene – only much better.
So first we need a way to read in our log files. Logstash stores its config in logstash.conf and reads file with the file input:
input {
file {
path => "/path/to/logs/localhost.2014-09-*.log"
# uncomment these lines if you want to reread the logs
# start_position => "beginning"
# sincedb_path => "/dev/null"
codec => multiline {
pattern => "^%{MONTH}"
what => "previous"
negate => true
}
}
}
There are some interesting things to note here. We use wildcards to match the desired input files. If we want to reread one or more of the log files we need to tell logstash to start from the beginning of the file and forget that the file was already read. Logstash remembers the position and the last time the file was read in a sincedb_path to ignore that we just specify /dev/null as a path. Inputs (and outputs) can have codecs. Here we join the lines in the log which do not start with a month. This helps us to record stack traces or multiline log entries as one event.
Add an output to stdout to the config file:
output {
stdout {
codec => rubydebug{}
}
}
Start logstash with
logstash -f logstash.conf --verbose
and you should see your log entries as json output with the line in the field message.
To analyse the events we need to categorise them or tag them for this we use the grep filter:
filter {
grep {
add_tag => ["request_started"]
match => ["message", "Information: .* Started .*"]
drop => false
}
}
Grep normally drops all non matching events, so we need to pass drop => false. This filter adds a tag to all events with the message field matching our regexp. We can add filters for matching the completed and error events accordingly:
grep {
add_tag => ["request_completed"]
match => ["message", "Information: .* Completed .*"]
drop => false
}
grep {
add_tag => ["error"]
match => ["message", "\:\:Error"]
drop => false
}
Now we know which event starts and which ends a request but how do we extract the duration and the request id? For this logstash has a filter named grok. One of the more powerful filters it can extract information and store them into fields via regexps. Furthermore it comes with predefined expressions for common things like timestamps, ip addresses, numbers, log levels and much more. Take a look at the source to see a full list. Since these patterns can be complex there’s a handy little tool with which you can test your patterns called grok debug.
If we want to extract the URL from the started event we could use:
grok {
match => ["message", ".* \[%{TIMESTAMP_ISO8601:timestamp} \#%{NUMBER:}\].*%{LOGLEVEL:level} .* \[%{UUID:request_id}\] Started %{WORD:method} \"%{URIPATHPARAM:uri}\" for %{IP:} at %{GREEDYDATA:}"]
}
For the duration of the completed event it looks like:
grok {
match => ["message", ".* \[%{TIMESTAMP_ISO8601:timestamp} \#%{NUMBER:}\].*%{LOGLEVEL:level} .* \[%{UUID:request_id}\] Completed %{NUMBER:http_code} %{GREEDYDATA:http_code_verbose} in %{NUMBER:duration:float}ms (\((Views: %{NUMBER:duration_views:float}ms \| )?ActiveRecord: %{NUMBER:duration_active_record:float}ms\))?"]
}
Grok patterns are inside of %{} like %{NUMBER:duration:float} where NUMBER is the name of the pattern, duration is the optional field and float the data type. As of this writing grok only supports floats or integers as data types, everything else is stored as string.
Storing the events in elasticsearch is straightforward replace or add to your stdout output an elasticsearch output:
output {
elasticsearch {
protocol => "http"
host => localhost
index => myindex
}
}
Looking at the events you see that start events contain the URL and the completed events the duration. For analysing it would be easier to have them in one place. But the default filters and codecs do not support this. Fortunately it is easy to develop your own custom filter. Since logstash is written in JRuby, all you need to do is write a Ruby class that implements register and filter:
require "logstash/filters/base"
require "logstash/namespace"
class LogStash::Filters::Transport < LogStash::Filters::Base
# Setting the config_name here is required. This is how you
# configure this filter from your logstash config.
#
# filter {
# transport { ... }
# }
config_name "transport"
milestone 1
def initialize(config = {})
super
@threadsafe = false
@running = Hash.new
end
def register
# nothing to do
end
def filter(event)
if event["tags"].include? 'request_started'
@running[event["request_id"]] = event["uri"]
end
if event["tags"].include? 'request_completed'
event["uri"] = @running.delete event["request_id"]
end
end
end
We name the class and config name ‘transport’ and declare it as milestone 1 (since it is a new plugin). In the filter method we remember the URL for each request and store it in the completed event. Insert this into a file named transport.rb in logstash/filters and call logstash with the path to the parent of the logstash dir.
logstash --pluginpath . -f logstash.conf --verbose
All our events are now in elasticsearch point your browser to http://localhost:9200/_search?pretty or where your elasticsearch is running and it should return the first few events. You can test some queries like _search?q=tags:request_completed (to see the completed events) or _search?q=duration:[1000 TO *] to get the events with a duration of 1000 ms and more. Now to the questions we want to be answered: what are the worst top ten response times by URL? For this we need to group the events by URL (field uri) and calculate the average duration:
curl -XPOST 'http://localhost:9200/_search?pretty' -d '
{
"size":0,
"query": {
"query_string": {
"query": "tags:request_completed AND timestamp:[7d/d TO *]"
}
},
"aggs": {
"group_by_uri": {
"terms": {
"field": "uri.raw",
"min_doc_count": 1,
"size":10,
"order": {
"avg_per_uri": "desc"
}
},
"aggs": {
"avg_per_uri": {
"avg": {"field": "duration"}
}
}
}
}
}'
See that we use uri.raw to get the whole URL. Elasticsearch separates the URL by the /, so grouping by uri would mean grouping by every part of the path. now-7d/d means 7 days ago. All groups of events are included but if we want to limit our aggregation to groups with a minimum size we need to alter min_doc_count. Now we have an answer but it is pretty unreadable. Why not have a website with a list?
Since we don’t need a whole web app we could just use Angular and the elasticsearch JavaScript API to write a small page. This page displays the top ten list and when you click on one it lists all events for the corresponding URL.
<!DOCTYPE html>
<html>
<head>
<script type="text/javascript" src="https://ajax.googleapis.com/ajax/libs/angularjs/1.2.11/angular.min.js"></script>
<script type="text/javascript" src="elasticsearch-js/elasticsearch.angular.js"></script>
<script type="text/javascript" src="monitoring.js"></script>
<link rel="stylesheet" href="http://netdna.bootstrapcdn.com/bootstrap/3.1.0/css/bootstrap.min.css">
<link rel="stylesheet" href="http://netdna.bootstrapcdn.com/bootstrap/3.1.0/css/bootstrap-theme.min.css">
</head>
<body>
<div ng-app="Monitoring" class="container" ng-controller="Monitoring">
<div class="col-md-6">
<h2>Last week's top ten slowest requests</h2>
<table class="table">
<thead>
<tr>
<th>URL</th>
<th>Average Response Time (ms)</th>
</tr>
</thead>
<tbody>
<tr ng-repeat="request in top_slow track by $index">
<td><a href ng-click="details_of(request.key)">{{request.key}}</a></td>
<td>{{request.avg_per_uri.value}}</td>
</tr>
</tbody>
</table>
</div>
<div class="col-md-6">
<h3>Details</h3>
<table class="table">
<thead>
<tr>
<th>Logs</th>
</tr>
</thead>
<tbody>
<tr ng-repeat="line in details track by $index">
<td>{{line._source.message}}</td>
</tr>
</tbody>
</table>
</div>
</div>
</body>
</html>
And the corresponding Angular app:
var module = angular.module("Monitoring", ['elasticsearch']);
module.service('client', function (esFactory) {
return esFactory({
host: 'localhost:9200'
});
});
module.controller('Monitoring', ['$scope', 'client', function ($scope, client) {
var indexName = 'myindex';
client.search({
index: indexName,
body: {
"size":0,
"query": {
"query_string": {
"query": "tags:request_completed AND timestamp:[now-1d/d TO *]"
}
},
"aggs": {
"group_by_uri": {
"terms": {
"field": "uri.raw",
"min_doc_count": 1,
"size":10,
"order": {
"avg_per_uri": "desc"
}
},
"aggs": {
"avg_per_uri": {
"avg": {"field": "duration"}
}
}
}
}
}
}, function(error, response) {
$scope.top_slow = response.aggregations.group_by_uri.buckets;
});
$scope.details_of = function(url) {
client.search({
index: indexName,
body: {
"size": 100,
"sort": [
{ "timestamp": "asc" }
],
"query": {
"query_string": {
"query": 'timestamp:[now-1d/d TO *] AND uri:"' + url + '"'
}
},
}
}, function(error, response) {
$scope.details = response.hits.hits;
});
};
}]);
This is just a start. Now we could filter out the errors, combine logs from different sources or write visualisations with d3. At least we see where performance problems lie and take further steps at the right places.