There are many good reasons to write unit tests for your code. Most of them are abstract enough that it might be hard to see the connection to your current work:
- Increase the test coverage
- Find bugs
- Guide future changes
- Explain the code
- etc.
I’m not saying that these goals aren’t worth it. But they can feel remote and not imperative enough. If your test coverage is high enough for the (mostly arbitrary) threshold, can’t we let the tests slip a bit this time? If I don’t know about future changes, how can I write guidelining tests for them? Better wait until I actually know what I need to know.
Just like that, the tests don’t get written or not written in time. Writing them after the fact feels cumbersome and yields subpar tests.
Finding motivation by stating your motivation
One thing I do to improve my testing habit is to state my motivation why I’m writing the test in the first place. It seemed to boil down to two main motivations:
- #Requirement: The test ensures that an explicit goal is reached, like a business rule that is spelled out in the requirement text. If my customer wants the value added tax of a price to be 19 % for baby food and 7 % for animal food, that’s a direct requirement that I can write unit tests for.
- #Bugfix: The test ensures the perpetual absence of a bug that was found in production (or in development and would be devastating in production). These tests are “tests that should have been there sooner”. But at least, they are there now and protect you from making the same mistake twice.
A code example for a #Requirement test looks like this:
/**
* #Requirement: https://ticket.system/TICKET-132
*/
@Test
void reduced_VAT_for_animal_food() {
var actual = VAT.addTo(
new NetPrice(10.00),
TaxCategory.animalFood
);
assertEquals(
new GrossPrice(10.70),
actual
);
}If you want an example for a #Bugfix test, it might look like this:
/**
* #Bugfix: https://ticket.system/TICKET-218
*/
@Test
void no_exception_for_zero_price() {
try {
var actual = VAT.addTo(
NetPrice.zero,
TaxCategory.general
);
assertEquals(
GrossPrice.zero,
actual
);
} catch (ArithmeticException e) {
fail(
"You messed up the tax calculation for zero prices (again).",
e
);
}
}In my mind, these motivations correlate with the second rule of the “ATRIP rules for good unit tests” from the book “Pragmatic Unit Testing” (first edition), which is named “Thorough”. It can be summarized like this:
- all mission critical functionality needs to be tested
- for every occuring bug, there needs to be an additional test that ensures that the bug cannot happen again
The first bullet point leads to #Requirement-tests, the second one to #Bugfix-tests.
An overshadowed motivation
But recently, we discovered a third motivation that can easily be overshadowed by #Requirement:
- #Assumption: The test ensures a fact that is not stated explicitly by the requirement. The code author used domain knowledge and common sense to infer the most probable behaviour of the functionality, but it is a guess to fill a gap in the requirement text.
This is not directly related to the ATRIP rules. Maybe, if one needs to fit it into the ruleset, it might be part of the fifth rule: “Professional”. The rule states that test code should be crafted with care and tidyness, that it is relevant even if it doesn’t get shipped to the customer. But this correlation is my personal opinion and I don’t want my interpretation to stop you from finding your own justification why testing assumptions is worth it.
How is an assumption different from a requirement? The requirement is written down somewhere else, too and not just in the code. The assumption is necessary for the code to run and exhibit the requirements, but it’s only in the code. In the mind of the developer, the assumption is a logical extrapolation from the given requirements. “It can’t be anything else!” is a typical thought about it. But it is only “written down” in the mind of the developer, nowhere else.
And this is a perfect motivation for a targeted unit test that “states the obvious”. If you tag it with #Assumption, it makes it clear for the next developer that the actual content of the corresponding coded fact is more likely to change than other facts, because it wasn’t required directly.
So if you come across an unit test that looks like this:
/**
* #Assumption: https://ticket.system/TICKET-132
*/
@Test
void normal_VAT_for_clothing() {
var actual = VAT.addTo(
new NetPrice(10.00),
TaxCategory.clothing
);
assertEquals(
new GrossPrice(11.90),
actual
);
}you know that the original author made an educated guess about the expected functionality, but wasn’t explicitly told and is not totally sure about it.
This is a nice way to make it clear that some of your code is not as rigid or expected as other code that was directly required by a ticket. And by writing an unit test for it, you also make sure that if anybody changes that assumed fact, they know what they are doing and are not just guessing, too.

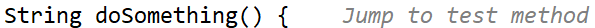
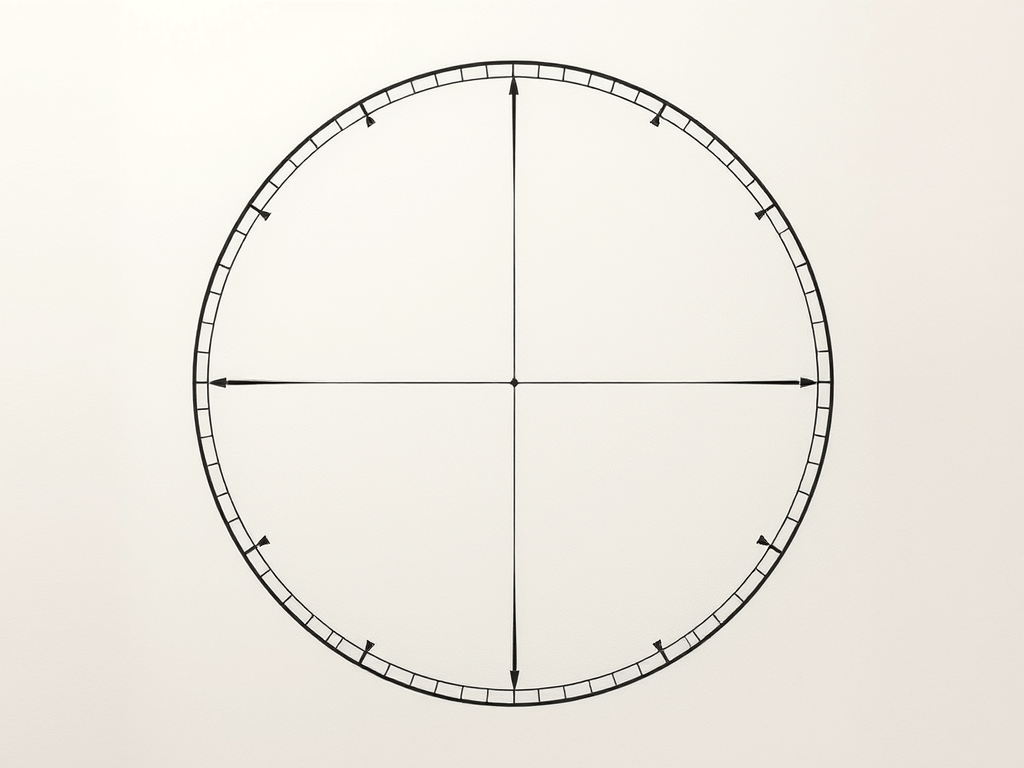
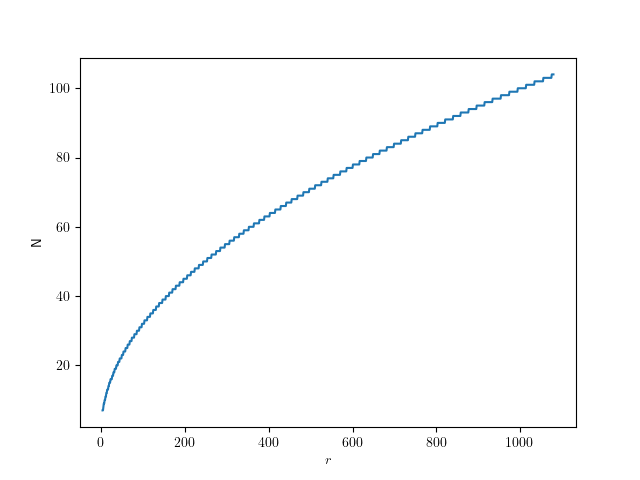
 for the job? For that, let’s look at the error that this approximation has.
for the job? For that, let’s look at the error that this approximation has. the inner radius is just the outer radius
the inner radius is just the outer radius  multiplied by the cosine of half of that:
multiplied by the cosine of half of that:  . So the error is
. So the error is  . I find it convenient to use relative error
. I find it convenient to use relative error  for the following, and set
for the following, and set 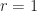 :
:
 ) circle, that means we should aim for a relative error of
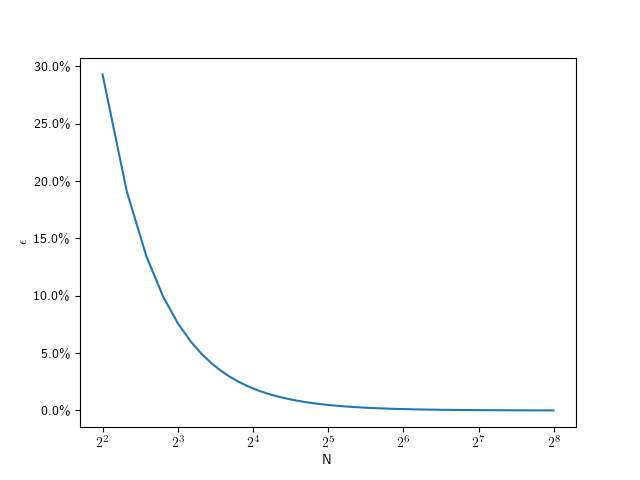
) circle, that means we should aim for a relative error of  . So we can solve the error equation above for N. Since the number of subdivisions should be an integer, we round it up:
. So we can solve the error equation above for N. Since the number of subdivisions should be an integer, we round it up:
 to
to  :
: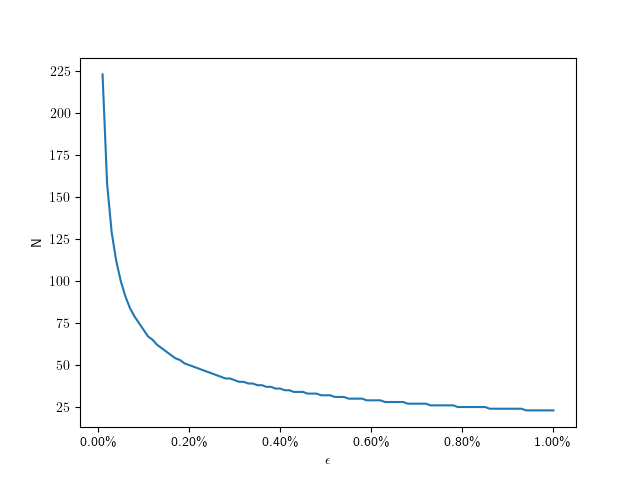
 to get:
to get: