Java Streams are like clean, connected pipes: data flows from one end to the other, getting filtered and transformed along the way. Everything works beautifully — as long as the pipe stays intact.
But what happens if you cut the pipe? Or if you throw rocks into it?
Both stop the flow, though in different ways. Let’s look at what that means for Java Streams.
Exceptions — Cutting the Pipe in Half
A stream is designed for pure functions. The same input gives the same output without side effects. Each element passes through a sequence of operations like map, filter, sorted. But when one of these operations throws an exception, that flow is destroyed. Exceptions are side effects.
Throwing an exception in a stream is like cutting the pipe right in the middle:
some water (data) might have already passed through, but nothing else reaches the end. The pipeline is broken.
Example:
var result = items.stream()
.map(i -> {
if(i==0) {
throw new InvalidParameterException();
}
return 10 / i;
})
.toList();
If you throws the exception, the entire stream stops. The remaining elements never get processed.
Uncertain Operations — Throwing Rocks into the Pipe
Now imagine you don’t cut the pipe — you just throw rocks into it.
Some rocks are small enough to pass.
Some are too big and block the flow.
Some hit the walls and break the pipe completely.
That’s what happens when you perform uncertain operations inside a stream that might fail in expected ways — for example, file reads, JSON parsing, or database lookups.
Most of the time it works, but when one file can’t be read, you suddenly have a broken flow. Your clean pipeline turns into a source of unpredictable errors.
var lines = files.stream()
.map(i -> {
try {
return readFirstLine(i); // throws IOException
}
catch (IOException e) {
throw new RuntimeException(e);
}
})
.toList();
The compiler does not allow checked exceptions like IOException in streams. Unchecked exceptions, such as RuntimeException, are not detected by the compiler. That’s why this example shows a common “solution” of catching the checked exception and converting it into an unchecked exception. However, this approach doesn’t actually solve the underlying problem; it just makes the compiler blind to it.
Uncertain operations are like rocks in the pipe — they don’t belong inside.
You never know whether they’ll pass, get stuck, or destroy the stream.
How to Keep the Stream Flowing
There are some strategies to keep your stream unbroken and predictable.
Prevent problems before they happen
If the failure is functional or domain-specific, handle it before the risky operation enters the stream.
Example: division by zero — a purely data-related, predictable issue.
var result = items.stream()
.filter(i -> i != 0)
.map(i -> 10 / i)
.toList();
Keep the flow pure by preparing valid data up front.
Represent expected failures as data
This also applies to functional or domain-specific failures. If a result should be provided for each element even when the operation cannot proceed, use Optional instead of throwing exceptions.
var result = items.stream()
.collect(Collectors.toMap(
i -> i,
i -> {
if(i == 0) {
return Optional.empty();
}
return Optional.of(10 / i);
}
));
Now failures are part of the data. The stream continues.
Keep Uncertain Operations Outside the Stream
This solution is for technical failures that cannot be prevent — perform it before starting the stream.
Fetch or prepare data in a separate step that can handle retries or logging.
Once you have stable data, feed it into a clean, functional pipeline.
var responses = fetchAllSafely(ids); // handle exceptions here
responses.stream()
.map(this::transform)
.toList();
That way, your stream remains pure and deterministic — the way it was intended.
Conclusion
A busted pipe smells awful in the basement, and exceptions in Java Streams smell just as bad. So keep your pipes clean and your streams pure.

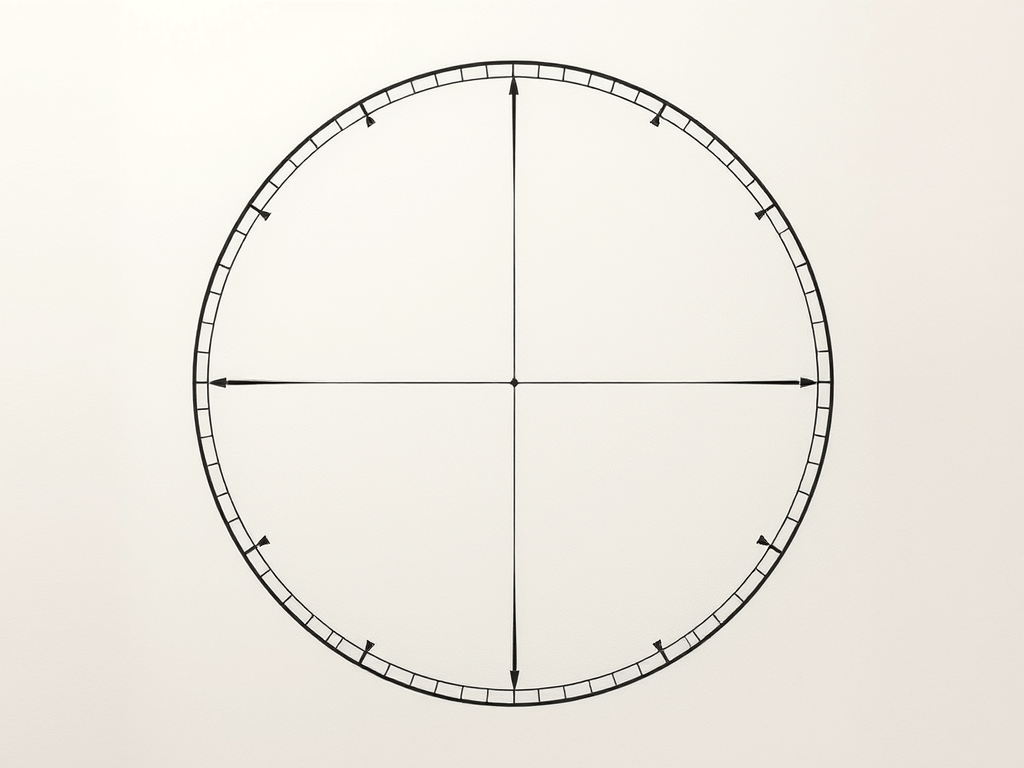
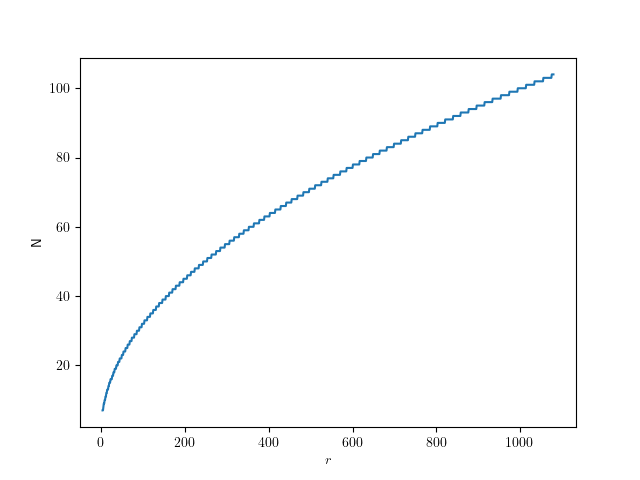
 for the job? For that, let’s look at the error that this approximation has.
for the job? For that, let’s look at the error that this approximation has. the inner radius is just the outer radius
the inner radius is just the outer radius  multiplied by the cosine of half of that:
multiplied by the cosine of half of that:  . So the error is
. So the error is  . I find it convenient to use relative error
. I find it convenient to use relative error  for the following, and set
for the following, and set 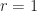 :
:
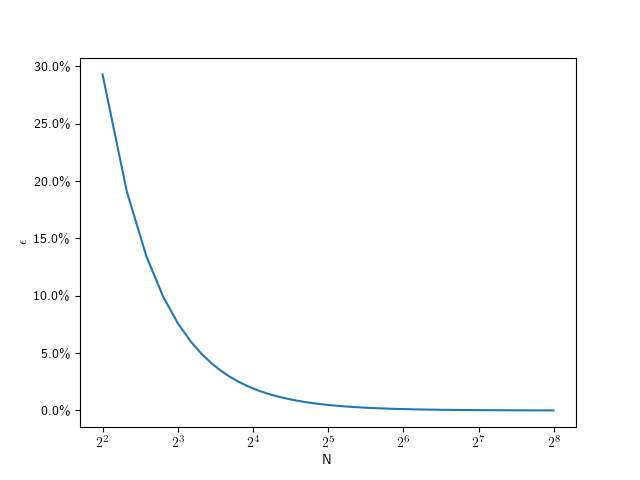
 ) circle, that means we should aim for a relative error of
) circle, that means we should aim for a relative error of  . So we can solve the error equation above for N. Since the number of subdivisions should be an integer, we round it up:
. So we can solve the error equation above for N. Since the number of subdivisions should be an integer, we round it up:
 to
to  :
: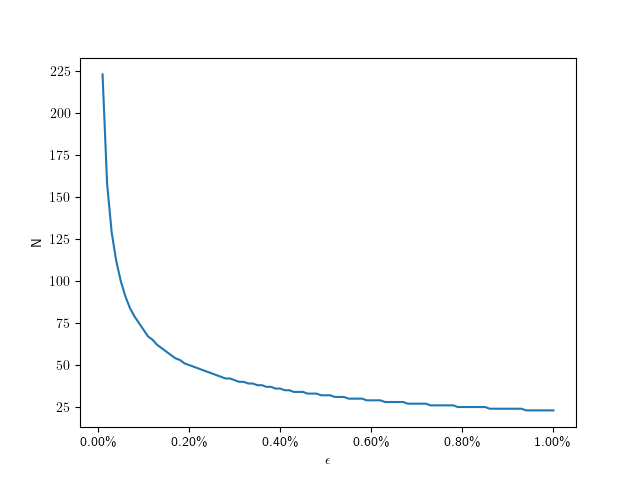
 to get:
to get: