Monorepos or “collection repositories” tend to grow over time. At some point, a part of them deserves its own life: independent deployments, a dedicated team, or separate release cycles.
The tricky part is obvious: How do you split out a subproject without losing its Git history?
The answer is a powerful tool called git-filter-repo.
Step 1: Clone the Repository into a New Directory
Do not work in your existing checkout. Instead, clone the repository into a fresh directory by running the following commands in Git Bash:
git clone ssh://git@github.com/project/Collection.git
cd Collection
We avoid working directly on origin and create a temporary branch:
git checkout -b split
This provides a safety net while rewriting history.
Step 2: Filter the Repository
Now comes the crucial step. Using git-filter-repo, we keep only the desired path and move it to the repository root.
Finally, push the rewritten history to the new repository:
git push -u origin main
That’s it — the new repository is ready, complete with a clean and meaningful history.
Conclusion
git-filter-repo makes it possible to split repositories precisely. Instead of copying files and losing context, you preserve history — which is invaluable for git blame, audits, and understanding how the code evolved.
When refactoring at repository level, history is not baggage. It’s documentation.
Once every while, I remember a public software engineering talk, held by Daniel and visited by me (not only), at a time before I accidentally started working for the Softwareschneiderei for several years, which turned out splendid – but I digress – and while the topic of that talk was (clearly) a culinary excursion about… how onions are superior to spaghetti… one side discussion spawned that quote (originally attributed to Michael Jackson e.g. here)
You know the First Rule of Optimization?
… don’t.
You know the Second Rule?
… don’t do it YET.
I like that a lot, because while we’ve all been at places where we knew a certain algorithm to be theoretically sub-optimal, measures of optimal is also “will it make my customer happy in a given time” and “will our programming resources be used at the most effective questions at hand”.
And that is especially tricky in software in which a customer starts with a wish like “I want a certain view on my data that I never had before” (thinking of spreadsheets, anyone?) and because they do not know what they will learn from that, no specification can even be thought-out. Call it “research” or “just horsing around”, but they will be thankful if you have a robust software that does the job, and customers can be very forgiving about speed issues, especially when they accumulate slowly over time.
Now we all know what N+1 query problems are (see e.g. Frederik’s post from some weeks ago), and even without databases, we are generally wary about any nested loops. But given the circumstances, one might write specific queries where you do allow yourself some.
There it not only “I have no time”. Sometimes you can produce much more readable code by doing nested queries. It can make sense. I mean, LINQ and the likes have a telling appearance, e.g. one can read
var plansForOffer = db.PlansFor(week).Where(p => p.Offers.Contains(offer.Id));
if (plansForOffer.Any()) {
lastDay = plansForOffer.Max(p => p.ProposedDay);
}
surely quite well; but here alone do the .Any() and the .Max() loop over similar data needlesly, and probably the helper PlansFor(…) does something like it, and then run that in a loop over many “offers” and quickly, there goes your performance down the drain only because your customers have now 40 instead of 20 entities.
To cut a long story short – with given .NET and Entity Framework in place, and in the situation of now-the-customer-finds-it-odd-that-some-queries-take-seven-minutes-to-completion, I did some profiling. In software where there are few users and ideally one instance of the software on one dedicated machine, memory is not the issue. So I contrasted the readable, “agile” version with some queries at startup and converged at the following pattern
var allOffers = await db.Offers
.Where(o => ... whatever interests you ... )
.Include(o => ... whatever EF relations you need ...)
.ToListAsync();
var allOfferIds = allOffsets
.Select(o => o.Id)
.ToArray();
var allPlans = await db.PlanningUnits
.Where(p => p.Contains(offer.Id))
.AsNoTracking()
.ToListAsync();
var allPlanIds = allPlans
.Select(p => p.Id)
.ToArray();
var allAppointments = await db.Appointments
.Where(a => allPlanIds.Contains(a.PlanId))
.AsNoTracking()
.ToListAsync();
var requiredSupervisors = allAppointments
.Select(a => a.Supervisor)
.Distinct()
.ToArray();
var requiredRooms = await db.Rooms
.Where(r => requiredSupervisors.Contains(r.SupervisorId)
.AsNoTracking()
.ToDictionaryAsync(r => r.Id);
// ...
return (
allOffers
.Select(o => CollectEverythingFromMemory(o, week, allOffers, allPlans, allAppointments, ...))
.ToDictionary(o => o.Id);
);
So the patterns are
Collect every data pool that you will possibly query as completely as you need
Load it into memory as .ToList() and where you can – e.g. in a server application, use await … .ToListAsync() in order to ease the the request thread pool
With ID lists and subsequent .Contains(), the .ToArray() call is even enough as arrays come with less overhead – although this is less important here.
Use .ToDictionaryAsync() for constant-time lookups (although more modern .NET/EF versions might have advanced functions there, this is the more basic fallback that worked for me)
Also, note the .AsNoTracking() where you are querying the database only (if not mutating any of this data), so EF can save all the memory overhead.
With that pattern, all inner queries transform to quite efficient in-memory-filtering of appearance like
and while this greatly blew up function signatures, and also required some duplication because these inner functions are not as modular, as stand-alone anymore, our customers now enjoyed a reduction in query size of really
Before: ~ 7 Minutes
After: ~ half a second
i.e. a 840-fold increase in performance.
Conclusion: not regretting much
It is somewhat of a dilemma. The point of “optimization…? don’t!” in its formulation as First and Second Rule holds true. I would not have written the first version of the algorithm in that consolidated .ToList(), .ToArray()., ToDictionary() shape when still in a phase where the customer gets new ideas every few days. You will need code that is easier to change, and easier to reckon about.
By the way – cf. the source again – ,the Third Rule is “Profile Before Optimizing”. When dealing with performance, it’s always crucial to find the largest culprit first.
And then, know that there are general structures which make such queries efficient. I can apply these thoughts to other projects and probably do not have to finely dig into the exact details of other algorithms, I just need to make that trade-off above.
Back before C++11, the recommended way to customize the behavior of an algorithm was to write a functor-struct, e.g. a small struct overloading operator(). E.g. for sorting by a specific key:
Of course, the same logic could be implemented with a free function, but that was often advised against because it was harder for the compiler to inline. Either way, if you had to supply some context variables, you were stuck with the verbose functor struct anyways. And it made it even more verbose. Something like this was common:
That all changed, of course, when lambdas were added to the language, and you could write the same thing as:
auto indirect_less = [&](T const& lhs, T const& rhs)
{ return indirection[lhs.key] < indirection[rhs.key]; };
At least as long as the indirection std::vector<> is in the local scope. But what if you wanted to reuse some more complicated functors in different contexts? In that case, I often found myself reverting back to the old struct pattern. Until recently I discovered there’s a lot nicer way, and I ask myself how I missed that for so long: functor factories. E.g.
auto make_indirect_less(std::vector const& indirection) {
return [&](T const& lhs, T const& rhs) { /* ... */ };
}
Much better than the struct! This has been possible since C++14’s return type deduction, so a pretty long time. Still, I do not think I have come across this pattern before. What about you?
As a software developer, you often write code that must run reliably in the background: data cleanup, periodic recalculations, imports, exports, and batch processing. Pushing this responsibility to external scripts or application-level schedulers is one way to do it, but it can add complexity and increase failure points.
Oracle’s job scheduling feature lets you move this logic into the database, close to the data it operates on, using plain SQL and PL/SQL. The result is simpler code, fewer moving parts, and background tasks that run predictably without constant supervision.
The Scheduler
This feature is provided by the DBMS_SCHEDULER package.
A basic example is a daily cleanup task. Suppose you have a table called ORDERS and you want to remove records older than five years every night. First, you create a stored procedure that performs the cleanup.
CREATE OR REPLACE PROCEDURE cleanup_old_orders IS
BEGIN
DELETE FROM orders
WHERE order_date < ADD_MONTHS(SYSDATE, -60);
COMMIT;
END;
/
Next, you create a scheduler job that runs this procedure every day at 2 a.m.:
In addition to defining jobs, it is important to understand the required privileges. To create and manage scheduler jobs, a user needs the CREATE JOB privilege. To create jobs in another schema, CREATE ANY JOB is required. Running jobs that use DBMS_SCHEDULER also requires EXECUTE privilege on the DBMS_SCHEDULER package.
If a job runs a stored procedure, the job owner must have direct privileges on the objects used by that procedure, not privileges granted through roles. For example, if a job deletes rows from the ORDERS table, the job owner must have a direct DELETE grant on that table. For external jobs, additional privileges such as CREATE EXTERNAL JOB and specific operating system credentials are required.
These rules ensure that jobs run securely and only perform actions explicitly allowed by the database administrator.
Monitoring
For monitoring, Oracle DB stores job execution details in system views. You can check whether a job is enabled and when it last ran with a simple query:
SELECT job_name, enabled, last_start_date, last_run_duration
FROM dba_scheduler_jobs
WHERE job_name = 'CLEANUP_OLD_ORDERS_JOB';
To see errors and execution history, you can query the job run details:
SELECT job_name, status, actual_start_date, run_duration, error#
FROM dba_scheduler_job_run_details
WHERE job_name = 'CLEANUP_OLD_ORDERS_JOB'
ORDER BY actual_start_date DESC;
These examples show how Oracle job scheduling works in practice. You define the SQL or PL/SQL logic, attach it to a schedule, and let the database handle execution and logging. This approach keeps automation close to the data, reduces manual intervention, and makes recurring tasks easier to manage and troubleshoot.
Modern (SQL) databases provide a multi-level hierarchy of separated contexts.
A database management system (DBMS) can manage multiple databases.
A database can contain multiple schemas.
A schema usually contains multiple tables, views, sequences and other objects.
Most of the time we developers only care about our database and the objects it contains – ignoring schemas and the DBMS.
In PostgreSQL instances this means we are using the default schema – usually called public – without mentioning it anywhere. Neither in the connection string or in any queries.
Ok, and why does all of the above even matter?
Special situations
Sometimes customers or operators require us to use special schemas in certain databases. When we do not have full control over our database deployment and usage we have to adapt to the situation we encounter.
Camel-casing
One thing I really advise against is using upper case names for tables, columns and so on. SQL itself is not case sensitive but many DBMSes differentiate case when it comes to naming. So they require you to use double-quotes to reference mixed-case objects like schemas and tables, e.g. "MyImportantTable". Imho it is far better to use only lower case letters and use snake_case for all names.
Multiple schemas in one database
I do not endorse using multiple names schemas in one database. Most of the time you do not need this level of separation and can simply use multiple databases in the same DBMS with their default schemas. That way you do not have to specify the schema in your queries.
What if you are required to use a non-default schema? At least for PostgreSQL you can modify your login role to change the search path. So you can leave all your queries and maybe other deployments untouched and without some schema name scattered all around your project:
-- instead of specifying schema name like
select * from "MyTargetSchema".my_table;
-- you can alter the search path of your role
alter role my_login set search_path = public,"MyTargetSchema";
-- to only write
select * from my_table;
Wrapping it up
Today’s software systems are quite complex and the problems we are trying to solve with them have their own, ever growing complexity. So when using DBMSes follow common advice like the above to reduce complexity in your solution even if it seems to be mandated.
Sometimes there are easy to follow conventions or configuration options that can reduce your burden as a developer even if you do not have complete control over the relevant parts of the deployment environment.
One of our customers has the requirement to enter data into a large database while being out in the field, potentially without any internet connection. This is a diminishing problem with the availability of satellite-based internet access, but it can be solved in different ways, not just the obvious “make internet happen” way.
One way to solve the problem is to analyze the customer’s requirements and his degrees of freedom – the things he has some leeway over. The crucial functionality is the safe and correct digital entry of the data. It would suffice to use a pen and a paper or an excel sheet if the mere typing of data was the main point. But the data needs to be linked to existing business entities and has some business rules that need to be obeyed. Neither paper nor excel would warn the user if a business rule is violated by the new data. The warning or error would be delayed until the data needs to be copied over into the real system and then it would be too late to correct it. Any correction attempt needs to happen on site, on time.
One leeway part is the delay between the data recording and the transfer into the real system. Copying the data over might happen several days later, but because the data is exclusive to the geographical spot, there are no edit collisions to be feared. So it’s not a race for the central database, it’s more of an “eventual consistency” situation.
If you take those two dimensions into account, you might invent “single-use webapps”. These are self-contained HTML files that present a data entry page that is dynamic enough to provide interconnected selection lists and real-time data checks. It feels like they gathered their lists and checks from the real system, and that is exactly what they did. They just did it when the HTML file was generated and not when it is used locally in the browser. The entry page is prepared with current data from the central database, written to the file and then forgotten by the system. It has no live connection and no ability to update its lists. It only exists for one specific data recording at one specific geographical place. It even has a “best before” date baked into the code so that it gives a warning if the preparation date and the usage date are too distant.
Like any good data entry form, the single-use webapp presents a “save data” button to the user. In a live situation, this button would transfer the data to the central database system, checking its integrity and correctness on the way. In our case, the checks on the data are done (using the information level at page creation time) and then, a transfer file is written to the local disk. The transfer file is essentially just the payload of the request that would happen in the live situation. It gets stored to be transferred later, when the connection to the central system is available again.
And what happens to the generated HTML files? The user just deletes them after usage. They only serve one purpose: To create one transfer file for one specific data entry task, giving the user the comfort and safety of the real system while entering the data.
What would your solution of the problem look like?
Disclaimer: While the idea was demonstrated as a proof of concept, it was not put into practice by the customer yet. The appeal of “internet access anywhere on the planet” is undeniably bigger and has won the competition of solutions for now. We would have chosen alike. The single-use webapp provides comfort and ease-of-use, but ubiquitous connectivity to the central system tops all other solutions and doesn’t need an extra manual or unusual handling.
When dividing decimal numbers in Java, some values—like 1 divided by 3—result in an infinite decimal expansion. In this blog post, I’ll show how such a calculation behaves using BigDecimal and BigFraction.
BigDecimal
Since this cannot be represented exactly in memory, performing such a division with BigDecimal without specifying a rounding mode leads to an “java.lang.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result”. Even when using MathContext.UNLIMITED or an effectively unlimited scale, the same exception is thrown, because Java still cannot produce a finite result.
BigDecimal a = new BigDecimal("1");
BigDecimal b = new BigDecimal("3");
BigDecimal c = a.divide(b);
By providing a scale – not MathContext.UNLIMITED – and a rounding mode, Java can approximate the result instead of failing. However, this also means the value is no longer mathematically exact. As shown in the second example, multiplying the rounded result back can introduce small inaccuracies due to the approximation.
BigDecimal a = new BigDecimal("1");
BigDecimal b = new BigDecimal("3");
BigDecimal c = a.divide(b, 100, RoundingMode.HALF_UP); // 0.3333333...
BigDecimal a2 = c.multiply(b); // 0.9999999...
When working with BigDecimal, it’s important to think carefully about the scale you actually need. Every additional decimal place increases both computation time and memory usage, because BigDecimal stores each digit and carries out arithmetic with arbitrary precision.
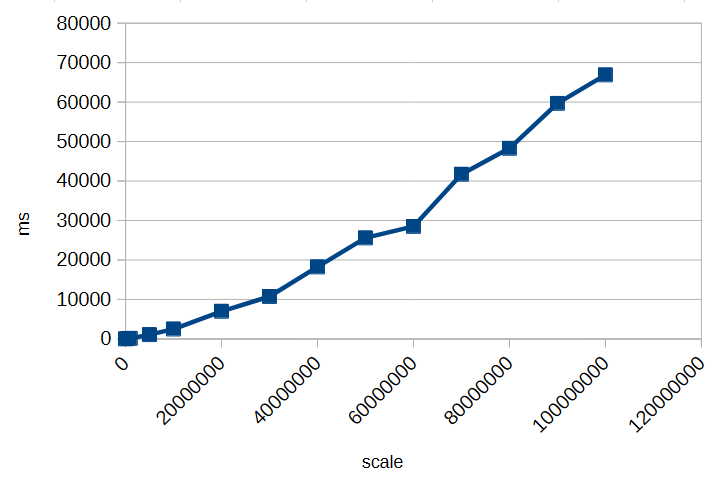
To illustrate this, here’s a small timing test for calculating 1/3 with different scales:
As you can see, increasing the scale significantly impacts performance. Choosing an unnecessarily high scale can slow down calculations and consume more memory without providing meaningful benefits. Always select a scale that balances precision requirements with efficiency.
However, as we’ve seen, decimal types like BigDecimal can only approximate many numbers when their fractional part is infinite or very long. Even with rounding modes, repeated calculations can introduce small inaccuracies.
But how can you perform calculations exactly if decimal representations can’t be stored with infinite precision?
BigFraction
To achieve truly exact calculations without losing precision, you can use fractional representations instead of decimal numbers. The BigFraction class from Apache Commons Numbers stores values as a numerator and denominator, allowing it to represent numbers like 1/3 precisely, without rounding.
import org.apache.commons.numbers.fraction.BigFraction;
BigFraction a = BigFraction.ONE;
BigFraction b = BigFraction.of(3);
BigFraction c = a.divide(b); // 1 / 3
BigFraction a2 = c.multiply(b); // 1
In this example, dividing 1 by 3 produces the exact fraction 1/3, and multiplying it by 3 returns exactly 1. Since no decimal expansion is involved, all operations remain mathematically accurate, making BigFraction a suitable choice when exact arithmetic is required.
BigFraction and Decimals
But what happens if you want to create a BigFraction from an existing decimal number?
At first glance, everything looks fine: you pass in a precise decimal value, BigFraction accepts it, and you get a fraction back. So far, so good. But if you look closely at the result, something unexpected happens—the number you get out is not the same as the one you put in. The difference is subtle, hiding far to the right of the decimal point—but it’s there. And there’s a simple reason for it: the constructor takes a double.
A double cannot represent most decimal numbers exactly. The moment your decimal value is passed into BigFraction.from(double), it is already approximated by the binary floating-point format of double. BigFraction then captures that approximation perfectly, but the damage has already been done.
Even worse: BigFraction offers no alternative constructor that accepts a BigDecimal directly. So whenever you start from a decimal number instead of integer-based fractions, you inevitably lose precision before BigFraction even gets involved. What makes this especially frustrating is that BigFraction exists precisely to allow exact arithmetic.
Creating a BigFraction from a BigDecimal correctly
To preserve exactness when converting a BigDecimal to a BigFraction, you cannot rely on BigFraction.from(double). Instead, you can use the unscaled value and scale of the BigDecimal directly:
In this case, BigFraction automatically reduces the fraction to its simplest form, storing it as short as possible. Even though the original numerator and denominator may be huge, BigFraction divides out common factors to minimize their size while preserving exactness.
BigFraction and Performance
Performing fractional or rational calculations in this exact manner can quickly consume enormous amounts of time and memory, especially when many operations generate very large numerators and denominators. Exact arithmetic should only be used when truly necessary, and computations should be minimized to avoid performance issues. For a deeper discussion, see The Great Rational Explosion.
Conclusion
When working with numbers in Java, both BigDecimal and BigFraction have their strengths and limitations. BigDecimal allows precise decimal arithmetic up to a chosen scale, but it cannot represent numbers with infinite decimal expansions exactly, and high scales increase memory and computation time. BigFraction, on the other hand, can represent rational numbers exactly as fractions, preserving mathematical precision—but only if constructed carefully, for example from integer numerators and denominators or from a BigDecimal using its unscaled value and scale.
In all cases, it is crucial to be aware of these limitations and potential pitfalls. Understanding how each type stores and calculates numbers helps you make informed decisions and avoid subtle errors in your calculations.
As many of our customers are operating somewhere in the technical or scientific field, we happen to get requests that are somewhat of the form
Well, so we got that spreadsheet managing our most important data and well… … it’s growing over our heads with 1000+ entries… … here are, sadly, multiple conflicting versions of it … … no one understands these formulae that Kevin designed … … we just want ONE super-concise number / graph from it … … actually, all of the above.
And while that scenario might be exaggerated for the sole reason of entertainment, at its core there’s something quite universal. Now there’s one thing to feel like the only adult in the room, throwing one’s hands up into the air, and then calculating the minimum expenses for a self-contained solution and while doing so, we still would strive for a simple proposal, that’s always quite a tightrope walk between the “this really needs not to be fancy” and the “but we can not violate certain standards either”.
And in such a case, your customer might happily agree with you – they do not want to rely on their spreadsheets, it just was too easy just to start with. And now they’re addicted.
The point of this post is this: If your customer has tabular data, there’s almost no “simple” data input interface you can imagine that is not absolutely outgunned by spreadsheets, or even text files. The sheer amount of conventions that nearly everyone already knows, don’t try to compete with some input fields and “Add entity” buttons and HTML <form>s.
This is no praise towards spreadsheet software at all. But consider the hidden costs that can wait behind a well-intended “simple data input form”.
For the very first draft of your software
do not build any form of data input interface, if you cannot exactly know that it will quickly empower the user to something they can not do already.
Do very boldly state: Keep your spreadsheets, CSV, text files. I will work with them, not against them.
E.g. Offer something as “uncool” as a “(up) load file” button, or a field to paste generic text. You do not have to parse .xls, .xlsx, .ods files either. The message should be: Use whatever software you want to use, up to the point where it started to be a liability, not your friend anymore.
Do not be scared about “but what if they have wrong formatting”. Well then find the middle ground – what kind of data should you really sanitize, what can you straightout reject?
Make it clear that you prioritize the actual problem of your customer. Examples:
if that problem is “too many sources-of-not-really-truth-anymore”, then your actual solution should focus on merging such data sources. But if that was the main problem of your customer, imagine them to always have some new long-lost-data-sources on some floppy disk, stashed in their comic book collection, or something.
if that problem is “we cannot see through that mess”, then your actual solution should focus on analyzing, on visualizing the important quantities.
if the problem is that Kevin starts writing new crazy formulae everyday and your customer is likely go out of business whenever he chooses to quit, then yes, maybe your actual solution is really in constructing a road block, but then rather in a long discussion about the actual use cases, not by just translating the crazy logic into Rust now, because “that’s safer”.
It is my observation, that a technically-accustomed customer is usually quite flexible in their ways. In some cases it really is your job to impose a static structure, and these are the cases in which they will probably approve of having that done to them. In other cases, e.g. their problem is a shape-shifting menace that they cannot even grasp, do not start with arbitrary abstractions, templates, schemas that will just slow them down. I mean – either you spend your day migrating their data all the time, and putting new input elements on their screen, or you spend your day solving their actual troubles.
Having a single source of truth is one of the big tenets of programming. It is easy to see why. If you want to figure out something about your program, or change something, you just go to the corresponding source.
One of the consequences of this is usually code duplication, but things can get a lot more complicated very fast, when you think of knowledge duplication or fragmentation, instead of just code. Quite unintuitively, duplication can actually help in this case.
Consider the case where you serialize an enum value, e.g. to a database or a file. Suddenly, you have two conceptual points that ‘know’ about the translation of your enum literals to a numeric or string value: The mapping in your code and the mapping implicitly stored in the serialization. None of these two points can be changed independently. Changing the serialized content means changing the source code and vice-versa.
You could still consider your initial enum to value mapping the single source of truth, but the problem is that you can easily miss disruptive changes. E.g. if you used the numeric value, just reordering the enumerated will break the serialization. If you used the text name of the enum, even a simple rename refactoring will break it.
So to deal with this, I often build my own single source of truth: a unit test that keeps track of such implicit value couplings. That way, the test can tell you when you are accidentally breaking things. Effectively, this means duplicating the knowledge of the mapping to a ‘safe’ space: One that must be deliberately changed, and resists accidentally being broken. And then that becomes my new single source of truth for that mapping.
When building apps that use a SQL database, it’s easy to run into performance problems without noticing. Many of these issues come from the way queries are written and used in the code. Below are seven common SQL mistakes developers make, why they happen, and how you can avoid them.
Not Using Prepared Statements
One of the most common mistakes is building SQL queries by concatenating strings. This approach not only introduces the risk of SQL injection but also prevents the database from reusing execution plans. Prepared statements or parameterized queries let the database understand the structure of the query ahead of time, which improves performance and security. They also help avoid subtle bugs caused by incorrect string formatting or escaping.
// Vulnerable and inefficient
String userId = "42";
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users WHERE id = " + userId);
// Safe and performant
String sql = "SELECT * FROM users WHERE id = ?";
PreparedStatement ps = connection.prepareStatement(sql);
ps.setInt(1, 42);
ResultSet rs = ps.executeQuery();
The N+1 Query Problem
The N+1 problem happens when an application fetches a list of items and then runs a separate query for each item to retrieve related data. For example, fetching a list of users and then querying each user’s posts in a loop. This results in one query to fetch the users and N additional queries for their posts. The fix is to restructure the query using joins or batch-fetching strategies, so all the data can be retrieved in fewer queries.
When queries filter or join on columns that do not have indexes, the database may need to scan entire tables to find matching rows. This can be very slow, especially as data grows. Adding the right indexes can drastically improve performance. It’s important to monitor slow queries and check whether indexes exist on the columns used in WHERE clauses, JOINs, and ORDER BY clauses.
Here’s how to create an index on an “orders” table for its “customer_id” column:
CREATE INDEX idx_orders_customer_id ON orders(customer_id);
Once the index is added, the query can efficiently find matching rows without scanning the full table.
Retrieving Too Much Data
Using SELECT * to fetch all columns from a table is a common habit, but it often retrieves more data than the application needs. This can increase network load and memory usage. Similarly, not using pagination when retrieving large result sets can lead to long query times and a poor user experience. Always select only the necessary columns and use LIMIT or OFFSET clauses to manage result size.
Some applications make many small queries in a single request cycle, creating high overhead from repeated database access. Each round-trip to the database introduces latency. Here’s an inefficient example:
for (int id : productIds) {
PreparedStatement ps = connection.prepareStatement(
"UPDATE products SET price = price * 1.1 WHERE id = ?"
);
ps.setInt(1, id);
ps.executeUpdate();
}
Instead of issuing separate queries, it’s often better to combine them or use batch operations where possible. This reduces the number of database interactions and improves overall throughput:
PreparedStatement ps = connection.prepareStatement(
"UPDATE products SET price = price * 1.1 WHERE id = ?"
);
for (int id : productIds) {
ps.setInt(1, id);
ps.addBatch();
}
ps.executeBatch();
Improper Connection Pooling
Establishing a new connection to the database for every query or request is slow and resource-intensive. Connection pooling allows applications to reuse database connections, avoiding the cost of repeatedly opening and closing them. Applications that do not use pooling efficiently may suffer from connection exhaustion or high latency under load. To avoid this use a connection pooler and configure it with appropriate limits for the workload.
Unbounded Wildcard Searches
Using wildcard searches with patterns like '%term%' in a WHERE clause causes the database to scan the entire table, because indexes cannot be used effectively. These searches are expensive and scale poorly. To handle partial matches more efficiently, consider using full-text search features provided by the database, which are designed for fast text searching. Here’s an example in PosgreSQL:
SELECT * FROM articles WHERE to_tsvector('english', title) @@ to_tsquery('database');
By being mindful of these common pitfalls, you can write SQL that scales well and performs reliably under load. Good database performance isn’t just about writing correct queries – it’s about writing efficient ones.
Have you faced any of these problems before? Every project is different, and we all learn a lot from the challenges we run into. Feel free to share your experiences or tips in the comments. Your story could help someone else improve their app’s performance too.