If you have to evaluate a new software project, draw the outline of the existing test types. If it doesn’t look like a pyramide, you might be in trouble. Here are some common non-pyramide outlines and what they mean.
A cornerstone of modern software development is developer testing. That means that developers are the primary authors of automated test code. In theory, that is a good thing and might look like the quality assurance department is out of work soon. In practice, we as a profession tried for nearly twenty years to install a culture of developer testing in our work and still end up with software projects that feature no automated tests at all (Side note: JUnit 1.0 was released in February of 1998).
What we know about automated tests
One piece of common understanding about developer testing is the test pyramide. Let’s iterate quickly what we know about it. There are different kinds of automated tests and the test pyramide differentiates three of them:
- Acceptance tests or UI tests are the heaviest type of automated test. They operate on the software from the outside, with the means of a real user and try to assert that real use cases are accomplishable.
- Integration tests often use several parts of the system in a test scenario that asserts the correct collaboration of the parts. Integration tests may take some time to come to a conclusion and utilize real hardware like network or disks.
- Unit tests tend to be small and quick and focus on a particular aspect of an “unit” like a class or entity aggregate. Their reach into the system should be short and might be forcefully restricted by employing mocks.
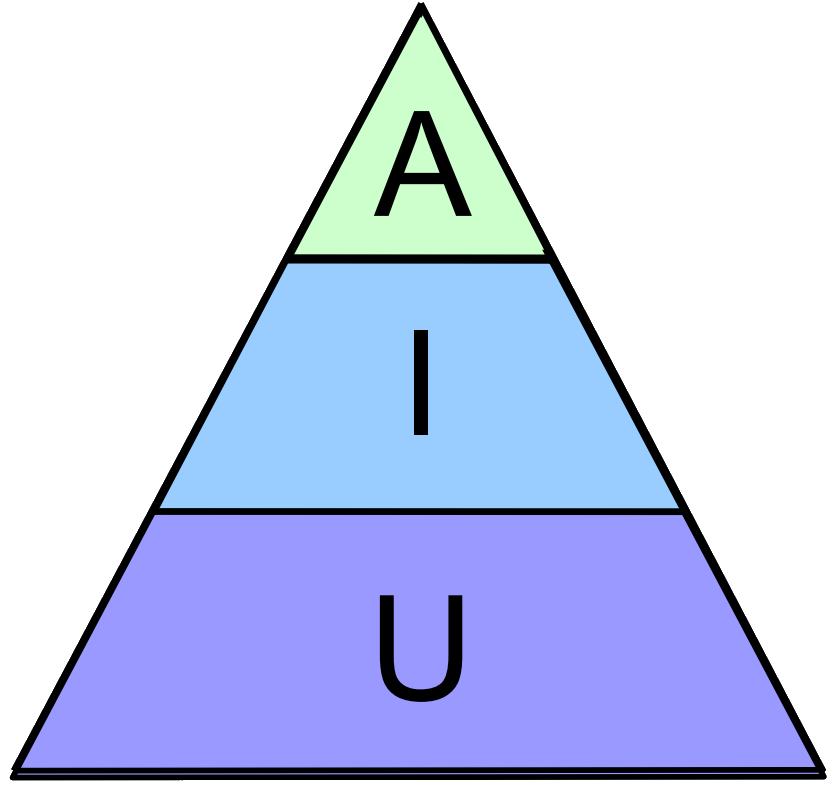
These three types, the A, I and U of automated tests, should come in different numbers. A good rule of thumb is that for every acceptance test, there might be up to one thousand unit tests. If you draw the quantities as areas, they appear in form of a pyramide. A small top of acceptance tests rests on a broader seating of integration tests that relies on a groundwork of many unit tests. A healthy test pyramide looks like this:
 Take this picture as an orientation, not as an absolute scale. But be sure to count your different test types from time to time.
Take this picture as an orientation, not as an absolute scale. But be sure to count your different test types from time to time.
Outlining the tests
This is actually one of the first things I do when I get introduced to a new and unknown code base. This happens quite often when I do consulting work for existing development teams. Have a look at the automated tests, determine their type and count their numbers. If it resembles anything close to the test pyramide, you’ve got a chance. If the resulting shape looks different, you might find this blog entry useful:
The Tower
 If you have a hard time finding any tests (because there are none) or you find only some half-assed attempts to produce a meaningful automated test suite, you look at a tower project. The tower is rather small in diameter, in the cases of absent tests it is nothing more than a thin vertical line (the “stick”). If you find a solid number of tests for every type, you’ve found a “block” project. Block projects usually don’t have a problem, but a history of test effort migration either from unit to acceptance tests or, more common, in the other direction. If you find a block, you are fine.
If you have a hard time finding any tests (because there are none) or you find only some half-assed attempts to produce a meaningful automated test suite, you look at a tower project. The tower is rather small in diameter, in the cases of absent tests it is nothing more than a thin vertical line (the “stick”). If you find a solid number of tests for every type, you’ve found a “block” project. Block projects usually don’t have a problem, but a history of test effort migration either from unit to acceptance tests or, more common, in the other direction. If you find a block, you are fine.
The tower, though, is a case of neglect. The project team might have started serious efforts to automated their tests, but got demotivated by intrinsic or extrinsic influences and abandoned the tests soon after their creation. Nobody has looked after them since and the only reason they still pass green is that they didn’t really test anything to begin with or only cover an area of the system that is as finished as it is boring. Topics like user management or utility classes are usually the first and only things that got tests in a tower scenario.
Don’t get me wrong, the tower indicates the absence of tests, but not the absence of willingness to write automated tests, unless the tower is really a stick. A team willing to invest in automated tests may only lack knowledge and coaching about the topic. Be sure to lead them bottom-up (unit tests first), though.
The Egg
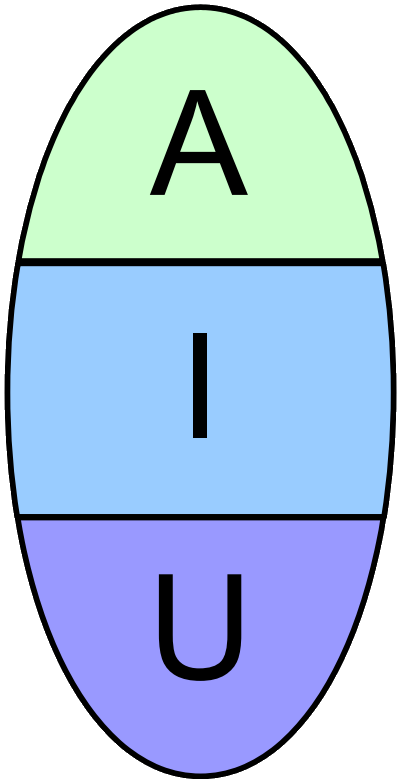
 If you’ve categorized and counted the tests and couldn’t find many acceptance or unit tests, you’ve found an egg. The egg consists of mostly integration tests that may lean into unit testing territory by asserting smallest bits of functionality here and there (often embedded in an overarching test storyline) or dip their toes into gui-based testing by asserting presentation-specific properties of widget objects. While they provide ample test coverage for the system, they also tie application logic and presentation details together and don’t help to separate domain code from the use cases.
If you’ve categorized and counted the tests and couldn’t find many acceptance or unit tests, you’ve found an egg. The egg consists of mostly integration tests that may lean into unit testing territory by asserting smallest bits of functionality here and there (often embedded in an overarching test storyline) or dip their toes into gui-based testing by asserting presentation-specific properties of widget objects. While they provide ample test coverage for the system, they also tie application logic and presentation details together and don’t help to separate domain code from the use cases.
The project team is probably proud of their test coverage and doesn’t see any value in differentiating the automated tests types, because “every test improves the situation”. The blindness to test types is the core problem that may be cured with training and coaching (I’ve found the ATRIP-rules to be particularly effective to distinguish integration and unit tests), but the symptoms, especially the lack of separation of concerns, have to be mitigated soon, too.
One way to start there is to break the tests down into their integration and their unit test parts. You can work from assertion to assertion and ask: is this necessary to ensure the current use case? If not, extract a new unit test focussed on only this one assertion.
As soon as you add a pedestal consisting of unit tests to your egg, you are on your best way to a healthy test pyramide.
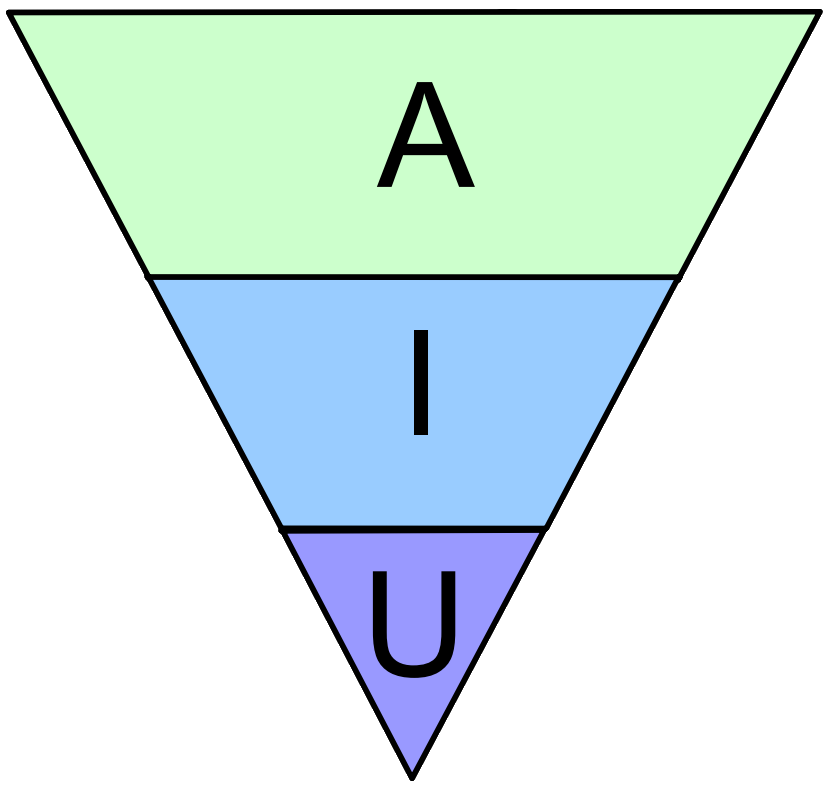
The Ice Cream Cone
 This is the most fearsome automated test outline in existence, even more dramatic than the stick. Usually, the project team is really enthusiastic about writing tests or at least follow order to do so, but they cannot test parts of the application in isolation. A really tragic case was a complex system that was so entangled with its database, through countless stored procedures that contributed to the application logic, that it was hopeless to think about tests without the database. And because every automated test had to start the whole system including the database, there was really no need to differentiate between application logic and presentation logic. It all became a gordic knot of dependencies that enforced the habit of writing elaborate automated GUI-based tests to test the smallest logic bits deep inside the core. It felt like eating single rice grains with overly long, flimsy wooden chopsticks that would break often.
This is the most fearsome automated test outline in existence, even more dramatic than the stick. Usually, the project team is really enthusiastic about writing tests or at least follow order to do so, but they cannot test parts of the application in isolation. A really tragic case was a complex system that was so entangled with its database, through countless stored procedures that contributed to the application logic, that it was hopeless to think about tests without the database. And because every automated test had to start the whole system including the database, there was really no need to differentiate between application logic and presentation logic. It all became a gordic knot of dependencies that enforced the habit of writing elaborate automated GUI-based tests to test the smallest logic bits deep inside the core. It felt like eating single rice grains with overly long, flimsy wooden chopsticks that would break often.
The ice cream cone is problematic because the project team needs to realize that their effort was mislead and the tests are all telling the bitter truth: the system’s architecture isn’t fit for proper automated tests. It’s not the tests, it’s you (or your architecture)! Nobody wants to hear that and more so, nobody wants to untangle the mess (without the help of a proper safety net consisting of automated tests). Pinning tests are probably helpful in this scenario.
But you need to turn the test pyramide around or the project team will suffocate by the overly costly test tax while increasing technical debt.
Epilogue
Please keep in mind that it’s not a problem in itself that your project doesn’t have a normal test pyramide. It’s great that you have automated tests at all! But your current test type distribution might not be as effective as possible, might be more expensive than necessary and might be not the right automated test setup for your development goals.
What are your stories with automated test setups? Care to share it with us in the comments?