Don’t be too alarmed by the title. Functions are immortal concepts and there’s nothing wrong with a getter method. Except when you write code under the rules of the Object Calisthenics (rule number 9 directly forbids getter and setter methods). Or when you try to adhere to the ideal of encapsulation, a cornerstone of object-oriented programming. Or when your code would really benefit from some other design choices. So, most of the time, basically. Nobody dies if you write a getter method, but you should make a concious decision for it, not just write it out of old habit.
One thing the Object Calisthenics can teach you is the immediate effect of different design choices. The rules are strict enough to place a lot of burden on your programming, so you’ll feel the pain of every trade-off. In most of your day-to-day programming, you also make the decisions, but don’t feel the consequences right away, so you get used to certain patterns (habits) that work well for the moment and might or might not work in the long run. You should have an alternative right at hands for every pattern you use. Otherwise, it’s not a pattern, it’s a trap.
Some alternatives
Here is an incomplete list of common alternatives to common patterns or structures that you might already be aware of:
- if-else statement (explicit conditional): You can replace most explicit conditionals with implicit ones. In object-oriented programming, calling polymorphic methods is a common alternative. Instead of writing if and else, you call a method that is overwritten in two different fashions. A polymorphic method call can be seen as an implicit switch-case over the object type.
- else statement: In the Object Calisthenics, rule 2 directly forbids the usage of else. A common alternative is an early return in the then-block. This might require you to extract the if-statement to its own method, but that’s probably a good idea anyway.
- for-loop: One of the basic building blocks of every higher-level programming language are loops. These explicit iterations are so common that most programmers forget their implicit counterpart. Yeah, I’m talking about recursion here. You can replace every explicit loop by an implicit loop using recursion and vice versa. Your only limit is the size of your stack – if you are bound to one. Recursion is an early brain-teaser in every computer science curriculum, but not part of the average programmer’s toolbox. I’m not sure if that’s a bad thing, but its an alternative nonetheless.
- setter method: The first and foremost alternative to a state-altering operation are immutable objects. You can’t alter the state of an immutable, so you have to create a series of edited copies. Syntactic sugar like fluent interfaces fit perfectly in this scenario. You can probably imagine that you’ll need to change the whole code dealing with the immutables, but you’ll be surprised how simple things can be once you let go of mutable state, bad conscience about “wasteful” heap usage and any premature thought about “performance”.
Keep in mind that most alternatives aren’t really “better”, they are just different. There is no silver bullet, every approach has its own advantages and drawbacks, both shortterm and in the long run. Your job as a competent programmer is to choose the right approach for each situation. You should make a deliberate choice and probably document your rationale somewhere (a project-related blog, wiki or issue tracker comes to mind). To be able to make that choice, you need to know about the pros and cons of as much alternatives as you can handle. The two lamest rationales are “I’ve always done it this way” and “I don’t know any other way”.
An alternative for get
In this blog post, you’ll learn one possible alternative to getter methods. It might not be the best or even fitting for your specific task, but it’s worth evaluating. The underlying principle is called “Tell, don’t Ask”. You convert the getter (aka asking the object about some value) to a method that applies a function on the value (aka telling the object to work with the value). But what does “applying” mean and what’s a function?
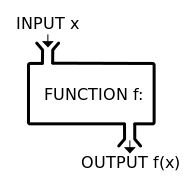 A function is defined as a conversion of some input into some output, preferably without any side-effects. We might also call it a mapping, because we map every possible input to a certain output. In programming, every method that takes a parameter (or several of them) and returns something (isn’t void) can be viewed as a function as long as the internal state of the method’s object isn’t modified. So you’ve probably programmed a lot of functions already, most of the time without realizing it.
A function is defined as a conversion of some input into some output, preferably without any side-effects. We might also call it a mapping, because we map every possible input to a certain output. In programming, every method that takes a parameter (or several of them) and returns something (isn’t void) can be viewed as a function as long as the internal state of the method’s object isn’t modified. So you’ve probably programmed a lot of functions already, most of the time without realizing it.
In Java 8 or other modern object-oriented programming languages, the notion of functions are important parts of the toolbox. But you can work with functions in Java since the earliest days, just not as convenient. Let’s talk about an example. I won’t use any code you can look at, so you’ll have to use your imagination for this. So you have a collection of student objects (imagine a group of students standing around). We want to print a list of all these students onto the console. Each student object can say its name and matriculation number if asked by plain old getters. Damn! Somebody already made the design choice for us that these are our duties:
- Iterate over all student objects in our collection. (If you don’t want to use a loop for this you know an alternative!)
- Ask each student object about its name and matriculation number.
- Carry the data over to the console object and tell the console to print both informations.
But because this is only in our imagination, we can go back in imagined time and eliminate the imagined choice for getters. We want to write our student objects without getters, so let’s get rid of them! Instead, each student object knows about their name and matriculation number, but cannot be asked directly. But you can tell the student object to supply these informations to the only (or a specific) method of an object that you give to it. Read the previous sentence again (if you’ve not already done it). That’s the whole trick. Our “function” is an object with only one method that happens to have exactly the parameters that can be provided by the student object. This method might return a formatted string that we can take to the console object or it might use the console itself (this would result in no return value and a side effect, but why not?). We create this function object and tell each student object to use it. We don’t ask the student object for data, we tell it to do work (Tell, don’t Ask).
In this example, the result is the same. But our first approach centers the action around our “main” algorithm by gathering all the data and then acting on it. We don’t feel pain using this approach, but we were forced to use it by the absence of a function-accepting method and the presence of getters on the student objects. Our second approach prepares the action by creating the function object and then delegates the work to the objects holding the data. We were able to use it because of the presence of a function-accepting method on the student objects. The absence of getters in the second approach is a by-product, they simply aren’t necessary anymore. Why write getters that nobody uses?
We can observe the following characteristics: In a “traditional”, imperative style with getters, the data flows (gets asked) and the functionality stays in place. In a Tell, don’t Ask style with functions, the data tends to stay in place while the functionality gets passed around (“flows”).
Weighing the options
This is just one other alternative to the common “imperative getter” style. As stated, it isn’t “better”, just maybe better suited for a particular situation. In my opinion, the “functional operation” style is not straight-forward and doesn’t pay off immediately, but can be very rewarding in the long run. It opens the door to a whole paradigm of writing sourcecode that can reveal inherent or underlying concepts in your solution domain a lot clearer than the imperative style. By eliminating the getter methods, you force this paradigm on your readers and fellow developers. But maybe you don’t really need to get rid of the getters, just reduce their usage to the hard cases.
So the title of this blog post is a bit misleading. Every time you write a getter, you’ve probably considered all alternatives and made the informed decision that a getter method is the best way forward. Every time you want to change that decision afterwards, you can add the function-accepting method right alongside the getters. No need to be pure or exclusive, just use the best of two worlds. Just don’t let the functions die (or never be born) because you “didn’t know about them” or found the style “unfamiliar”. Those are mere temporary problems. And one of them is solved right now. Happy coding!